端午第二天,在b站看Louis CK讲一些屎尿屁的笑话,他最新的专场是2023年1月的back to garden。随着年龄增长,他的笑话越来越没有底线,我也变老,更能无上限的跟着哈哈大笑。
Author: veteran
重新折腾我的宁芝PLUM atom6835g-T
从去年9月,就开始做倒计时准备,今年4月吧,提前把宁芝静电容键盘从办公室拿回家里。
这个键盘是22年6月份,也就是刚刚解封后从京东购买的,1059元人民币,刚刚在京东网站看了下,618也没降价多少,大概999到手吧。使用这种专业键盘的好处,是可以想对专注的进行敲击,手感和注意力似乎真的有关系。
不过,这个键盘那会家里,发现有几个配置和办公室不一样,比如win和mac键是相反的,Capslock也不能实现拼音/英文输入切换。更可气的是,Backspace和“|、”是对调的,让人有点抓狂。去郑州出差前,想花十分钟把键盘习惯理顺,不得如愿,只能携带罗技760这个太阳能键盘。
今天休假在家,领教了宁芝略带怪异的设置“哲学”,还好解决不错。
核心关键是,不管三七二十一,先同时按住键盘四角实现出场设置,然后按照键盘说明书来操作即可。

- 实现win/mac切换:同时按左ALT和右CMD三秒以上
- 实现capslock进行拼音英文切换:同时按左Ctrl和右CMD三秒以上
- backspace和“|、”切换:我不知道是如何实现的,一通乱按,就ok了。。。
- 查询键盘的型号:在键盘底部,可以看到键盘的型号,例如“Atom68EC(S)Ble”,只不过它的中文官方名称是“
几个在python runtime里的小技巧
有时候要在runtime里进行调试,例如测试下某个变量的值,我就问了chatgpt
me:how run python file in python run time
chatgpt:To run a Python file within another Python script at runtime, you can use the execfile() function, which allows you to execute a file as if it were a Python script. However, please note that the execfile() function is no longer available in Python 3.x.
Here's an example of how you can use execfile() in Python 2.x:
execfile('path/to/file.py')
If you are using Python 3.x, you can achieve a similar result using the exec() function. Here's an example:
with open('path/to/file.py', 'r') as file:
code = file.read()
exec(code)
In the above examples, replace 'path/to/file.py' with the actual path to the Python file you want to run. The file will be executed at runtime, and its code will be executed within the context of the running script.
Keep in mind that using execfile() or exec() to execute arbitrary code from external files can be a security risk, especially if the code comes from untrusted sources. Exercise caution when executing external code in this manner.
下面就是我在VS的终端界面里,执行的情况,很不错.
>>> with open('mnist_show.py', 'r') as file:
... code = file.read()
...
>>> exec(code)
我又问了chatgpt一个愚蠢的问题,使用了非常幼稚的英文
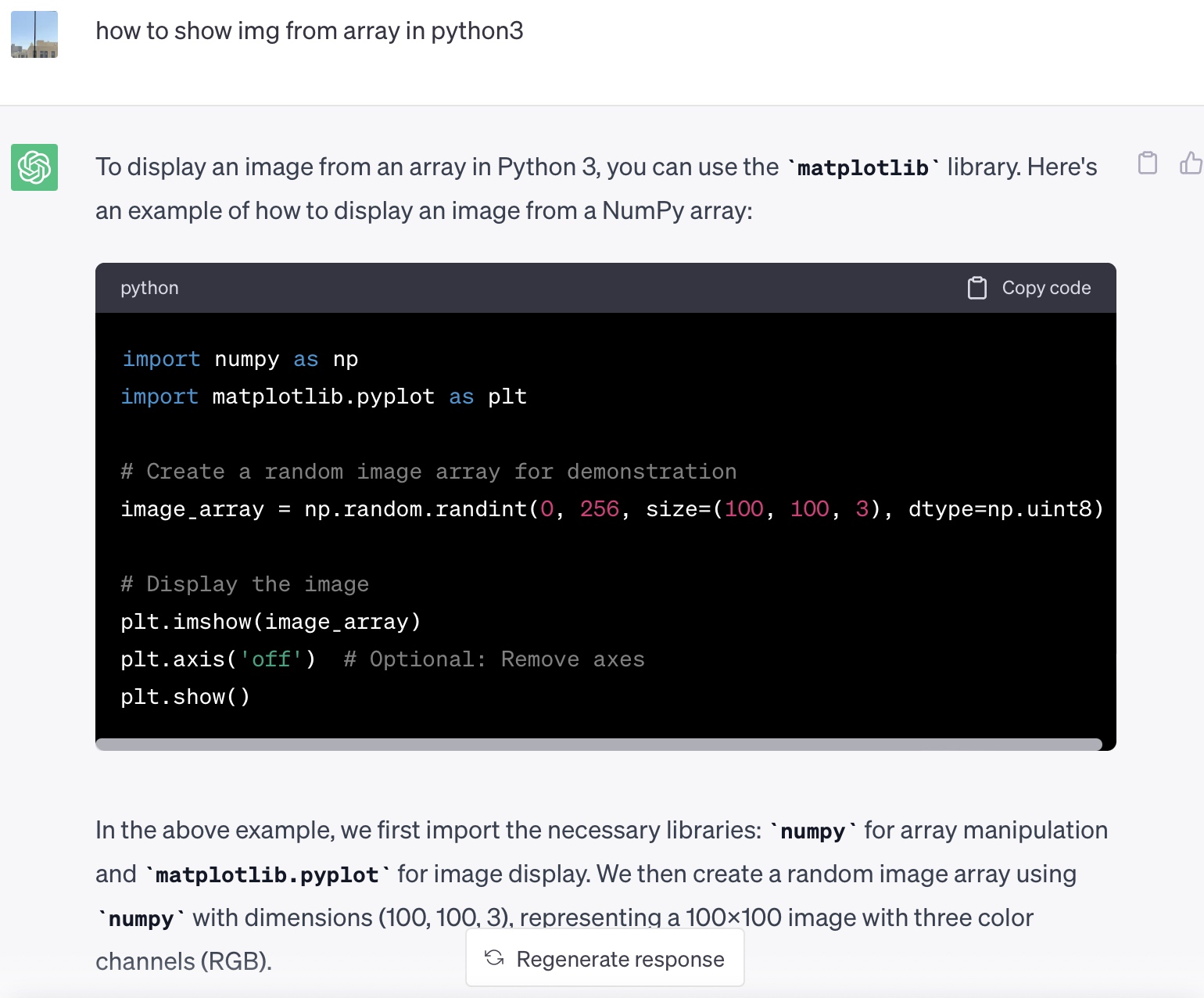
ChatGPT竟然给出了非常好的答案。
最近网上在讨论是否大模型会污染我们现实语言的环境,因为大量生成的预料会被用来进行训练,类似电路里“自激”的现象,同时有人在知乎的旅游问答专栏下,发现了大量明显是chatgpt给出的错误答案。进而引发了是不是chatgpt正在严重污染“简中”环境的问题。
我倒不担心,一个垃圾环境如何被污染的更脏呢?
反而我担心,chatgpt这么强大,人类在他面前就像一个小孩子,chatgpt就像一个至尊的王者,面对所有人类的错误、幼稚都采取宽容的态度,就像我刚刚使用的笨拙英文,他不纠正我,而是给出了正确答案。
这就好比给了人类大脑一个拐杖,大脑就开始了萎缩。
AI布道
今天在公众号里看到:
“Insider报道,德国一座教堂举办由ChatGPT和虚拟人组合提供的布道服务。300多人参加了布道,活动持续40分钟,内容包括布道,祷告和音乐,所有内容几乎完全由ChatGPT和一位维也纳大学的神学家、哲学家Jonas Simmerlein创作。 活动期间由四个不同的虚拟人带领,参与者褒贬不一,有人对此感到新奇,另一些人认为AI布道没有感情。”
似乎AI统治人世间的时代,提前来临了,毕竟神圣的布道活动是宗教仪式的核心,我参加过几次华东特色的基督教活动,整个活动的核心是几位教友陆续走上台来,从引导开始经历几个关键阶段,最终达至高潮。有时候他们会手拿圣经,或者简单到只握有一支麦克风,侃侃而谈。
很难想象,台上站立的不是年轻有朝气的教友,而是几块高清屏幕里的数字人,虽然声音已经惟妙惟肖,但两只手只能机械的重复哪些固定动作,僵硬的面部表情时刻在提醒台下教众,“它”的灵魂存在某块32G显存的GPU里,温度过高就会宕机。
这种感觉,在二十世纪的某一天,当神父约翰第一次举起麦克风,浑厚的男中音从1500W的百得音响传遍教堂时,下面虔诚的玛丽和迈瑞也曾有过类似的疑问,经过推挽放大和低通滤波器的声音,是不是就变得不那么纯粹而失去了宝贵的神性呢?
谁知道呢?
Further on up the road.
One sunny morning we’ll rise, I know.
文明养犬一件事
上海文明养犬一件事实战
最近要带着狗狗一起去加拿大,找了一家中介公司。在办理手续过程中,发现需要免疫证、打芯片,还要给狗狗办理一张上海的“城市户口”。
这个户口,原本是有的,只不过属于农村户口。我们居住在郊区,所以即使如上海的精细化管理,也随着距离人民广场的距离,精细化程度层层递减,街道在办理狗狗户口的时候,默认就给她了一张上海农村狗证,手续也想当的简单粗暴。一张名片大小的卡片,手写狗狗的名字和编号,工作人员顺手在微信里拍摄一张照片,就完成了户籍登记。
现在要出国了,才发现城乡不同名,拿着农村户口的小狗,竟然连出国的资格都没有。
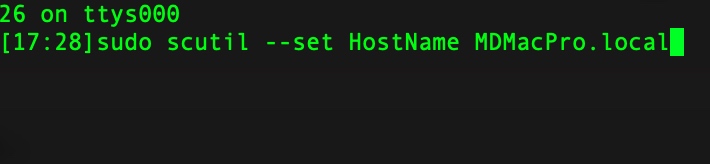
解决机器名称显示不正常
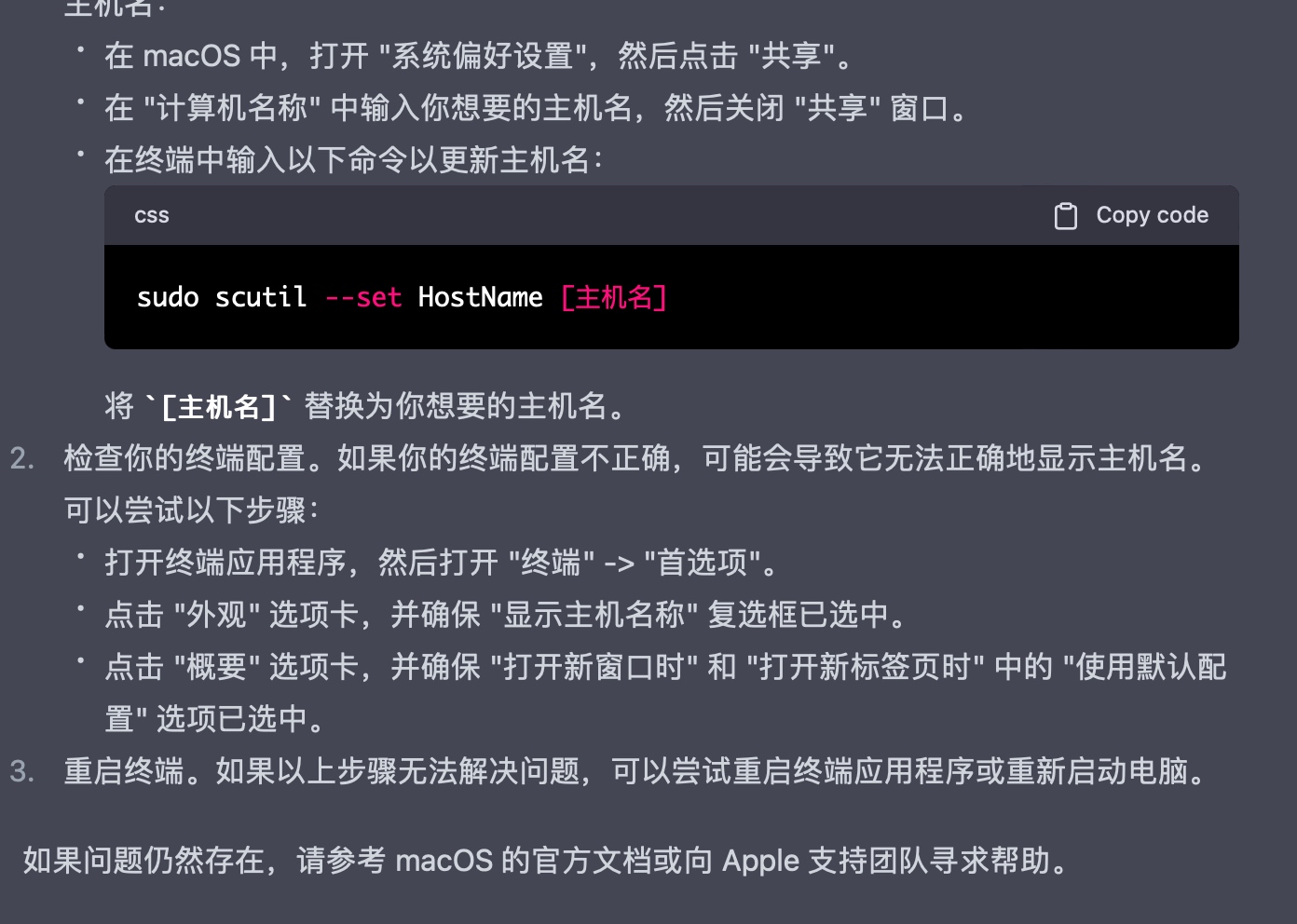
以下是实际操作
难从天上来,魔由心中起
西天路上,九九八十一难,唐僧四人遭遇的各种妖魔鬼怪,每个章节结束,都发现不过是天上各路神仙的小号而已。
要解决这个问题似乎也不难,放弃取经,各回各家。不过,回家是不是又树立了一个新的目标,回家路上是不是也会有新的妖怪出现?
似乎,只要心有所念,必定会有配套的烦恼涌现。
ChatGPT
最近迷上了chatGPT,逐渐得出一个结论,你使用chatGPT的效果,其实就是你和这个数字世界的边界,或者你和这个数字世界的熟悉程度。
例如
- 你只使用自然语言,那么就无法享受用机器语言和gpt聊天的乐趣;
- 局限在中文世界,chatgpt的输出范围,就要有限很多,而且会不自觉带上简中世界的特色,让你觉得在AI的多重宇宙中,无法自拔;
我越来越相信高斯分布,这个世界虽然很大,钟型曲线包裹下的芸芸众生,差异其实很小。而一旦你发现自己和长尾集合中的某个现象有了交集,一定不要犹豫、不要懒惰,要努力抓着它,这是让你摆脱中轴线的唯一机会。
2019年第一次听JJ介绍大模型的时候,除了惊奇外,没有多少想法,毕竟所需要的储备知识近乎于无,而且没有任何应用场景。虽然随后的几年,自己隐隐约约觉得,AI技术是真正的工具,使用这个工具,我可以更好的认识世界、认识自己,就像小时候利用脚蹼进行自由泳的练习一样。
中间几年无非疫情、各种无关紧要的政府项目,JJ也离职去开创自己的事业,虽然短短1年多,我从他这里没有学习到任何核心技术,但是这种人与人的差距,深深影响了我对高斯分布的看法。
终于,chatGPT来了,我梦寐以求的工具,竟然以这么戏剧化的方式将临身边。
一个例子
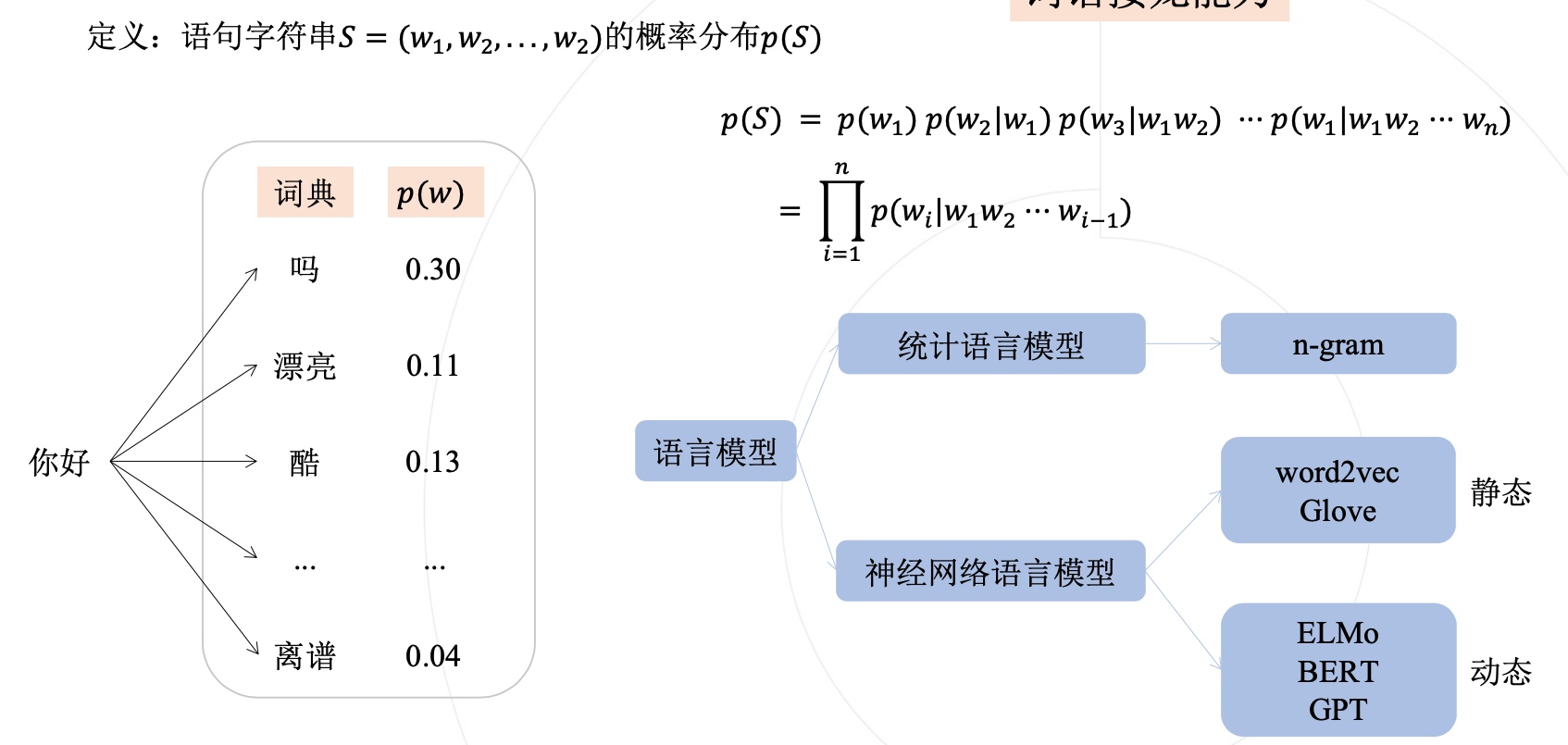
语句字符串S,就是一个句子,它的概率分布,可以是每个单词在这句话中出现的概率。
𝑝(𝑆) = 𝑝(𝑤1) 𝑝(𝑤2|𝑤1) 𝑝(𝑤3|𝑤1𝑤2) ··· 𝑝(𝑤1|𝑤1𝑤2 ··· 𝑤n)
公式的第一行,是将句子的概率分解为每个单词的条件概率相乘的形式, 例如,p(w2|w1)表示给定w1出现后,w2出现的概率。按照这样的方式,我们可以得到整个句子的概率分布。
总体来说,这个公式展示了语言模型如何基于先前的单词或文本序列,计算出下一个单词出现的概率,并进而计算整个句子的概率分布。
计算一个字符串中每个单词的出现概率可以通过以下步骤实现:
- 将字符串S分割成单词序列w1,w2,w3,…wi。
- 统计每个单词wi在字符串S中出现的次数。
- 计算每个单词wi在字符串S中出现的概率,即wi出现的次数除以字符串S的总长度。
例如,对于字符串S=“I love to eat pizza”,我们可以将其分割成单词序列[“I”, “love”, “to”, “eat”, “pizza”]。然后,我们可以统计每个单词在字符串S中出现的次数,如下所示:
-
"I"出现了1次
-
"love"出现了1次
-
"to"出现了1次
-
"eat"出现了1次
-
"pizza"出现了1次
最后,我们可以计算每个单词在字符串S中出现的概率,如下所示: -
P(“I”) = 1/5 = 0.2
-
P(“love”) = 1/5 = 0.2
-
P(“to”) = 1/5 = 0.2
-
P(“eat”) = 1/5 = 0.2
-
P(“pizza”) = 1/5 = 0.2
这个概率分布可以用于各种自然语言处理任务,例如语言模型、机器翻译和文本分类等。
大模型训练时,面对海量数据,没法承担高昂的标注成本,往往会采用自监督学习的方式。
自监督学习是一种无监督学习的方法,它通过利用数据的某些属性来设置伪监督任务来替换标准监督任务,从而使模型能够从大量未标记的数据中进行训练。
自监督学习的目标是学习到数据的有用表示,这些表示可以用于各种任务,例如分类、检测、分割和生成等。
自监督学习的一个例子是对于“损失函数中使用到的监督信息无需人工标注”的训练范式的一种统称,自监督学习可以用在预训练上,也可以用在实际任务本身的训练上,当然目前看来还是用在预训练上的情况显著更多.
基础概念
迁移学习(Transfer Learning)使基础模型成为可能
- 技术层面上,基础模型通过转移学习(Transfer Learning)(Thrun 1998)和规模(scale)得以实现。迁移学习的思想是将从一项任务中学习到的“知识”(例如,图像中的对象识别)应用于另一项任务(例如,视频中的活动识别)。
- 在深度学习中,预训练又是迁移学习的主要方法:在替代任务上训练模型(通常只是达到目的的一种手段),然后通过微调来适应感兴趣的下游任务。转移学习(Transfer Learning)使基础模型成为可能。
大规模化(scale)使基础模型更强大,因而GPT模型得以形成
- 大规模需要三个要素:
- (i)计算机硬件的改进——例如,GPU吞吐量和内存在过去四年中增加了10倍;
- (ii)Transformer模型架构的开发( Vaswani et al. 2017 ),该架构利用硬件的并行性来训练比以前更具表现力的模型;
- 以及(iii)更多训练数据的可用性。
- 基于Transformer的序列建模方法现在应用于文本、图像、语音、表格数据、蛋白质序列、有机分子和强化学习等,这些例子的逐步形成使得使用一套统一的工具来开发各种模态的基础模型这种理念得以成熟。例如,GPT-3( Brown et al. 2020 )与GPT-2的15亿参数相比, GPT-3具有1750亿个参数,允许上下文学习,在上下文学习中,只需向下游任务提供提示(任务的自然语言描述),语言模型就可以适应下游任务,这是产生的一种新兴属性。
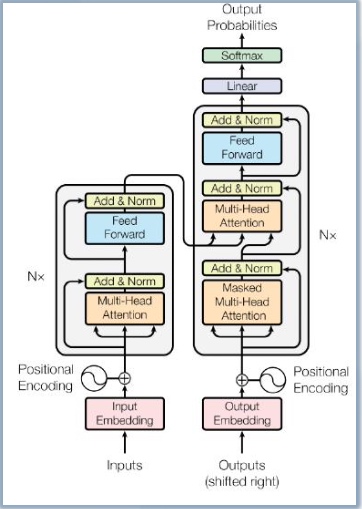
Transformer奠定了生成式AI领域的游戏规则
Transformer摆脱了人工标注数据集的缺陷,模型在质量上更优、 更易于并行化,所需训练时间明显更少,
Transformer通过成功地将其应用于具有大量和有限训练数据的分析,可以很好地推广到其他任务。
- 2017年,在Ashish Vaswani et.al 的论文《Attention Is All You Need》 中,考虑到主导序列转导模型基于编码器-解码器配置中的复杂递归或卷积 神经网络,性能最好的模型被证明还是通过注意力机制(attention mechanism)连接编码器和解码器,因而《Attention Is All You Need》 中提出了一种新的简单架构——Transformer,它完全基于注意力机制, 完全不用重复和卷积,因而这些模型在质量上更优,同时更易于并行化,并 且需要的训练时间明显更少。
- Transformer出现以后,迅速取代了RNN系列变种,跻身主流模型架构基 础。(RNN缺陷正在于流水线式的顺序计算)
Transformer模型架构如下图
解决xcode更新画菊花问题
按照xcode后,如果遇到更新,往往会出现各种问题,比如watch模拟器无法安装成功,或者就是更新的最后0.0001%总是完成不了,appstore里菊花转圈不断。
解决方法:
- 简单粗暴,删除xcode即可
- 去apple developer download下载离线安装版本,安装
我最近不太使用swift开发,所以决定删除xcode,顺便节省磁盘空间。
然而,删除xcode后,更新提示还是依然会出现,采取如下几步顺利接触更新提示。
关闭sip
- 重启mac,同时按住cmd+R启动恢复模式
- 进入恢复模式,启动terminal
csrutil disable
- 重启,进入如下目录,并删除和clt有关的系列文件
22-11-06/Users/xxxxx~%>cd Library/Apple/System/Library/Receipts
22-11-06/Users/XXXXX~%>sudo rm -rf com.apple.pkg.CLTools_*.*
- 再次进入恢复模式,启动terminal
- 启动sip
csrutil enable
重新定位clt工具
22-11-06/Users/xxxxx~%>sudo xcode-select -switch /
22-11-06/Users/XXXX~%>xcode-select -p
/Library/Developer/CommandLineTools
最后,更新brew
brew update
/etc/zshrc
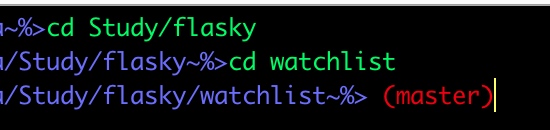
用最简洁的方式,在prompt里实现git branch的信息
增加parse_git_branch函数
final version
parse_git_branch() {
git branch 2> /dev/null | sed -e '/^[^*]/d' -e 's/* \(.*\)/ (\1)/'
}
PS1="%F{12}%D%d~%#>%f%F{red}\$(parse_git_branch)%f"
ZSH prompt的简单生成器
https://zsh-prompt-generator.site/
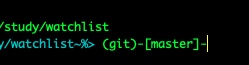
ZSH现实git branch的另外一种方法
autoload -Uz vcs_info
precmd_vcs_info() { vcs_info }
precmd_functions+=( precmd_vcs_info )
setopt prompt_subst
#RPROMPT=$vcs_info_msg_0_
PS1="%F{cyan}%D%d~%#>%f"$vcs_info_msg_0_
reference
add git branch name to bash prompt
https://scriptingosx.com/2019/07/moving-to-zsh-06-customizing-the-zsh-prompt/