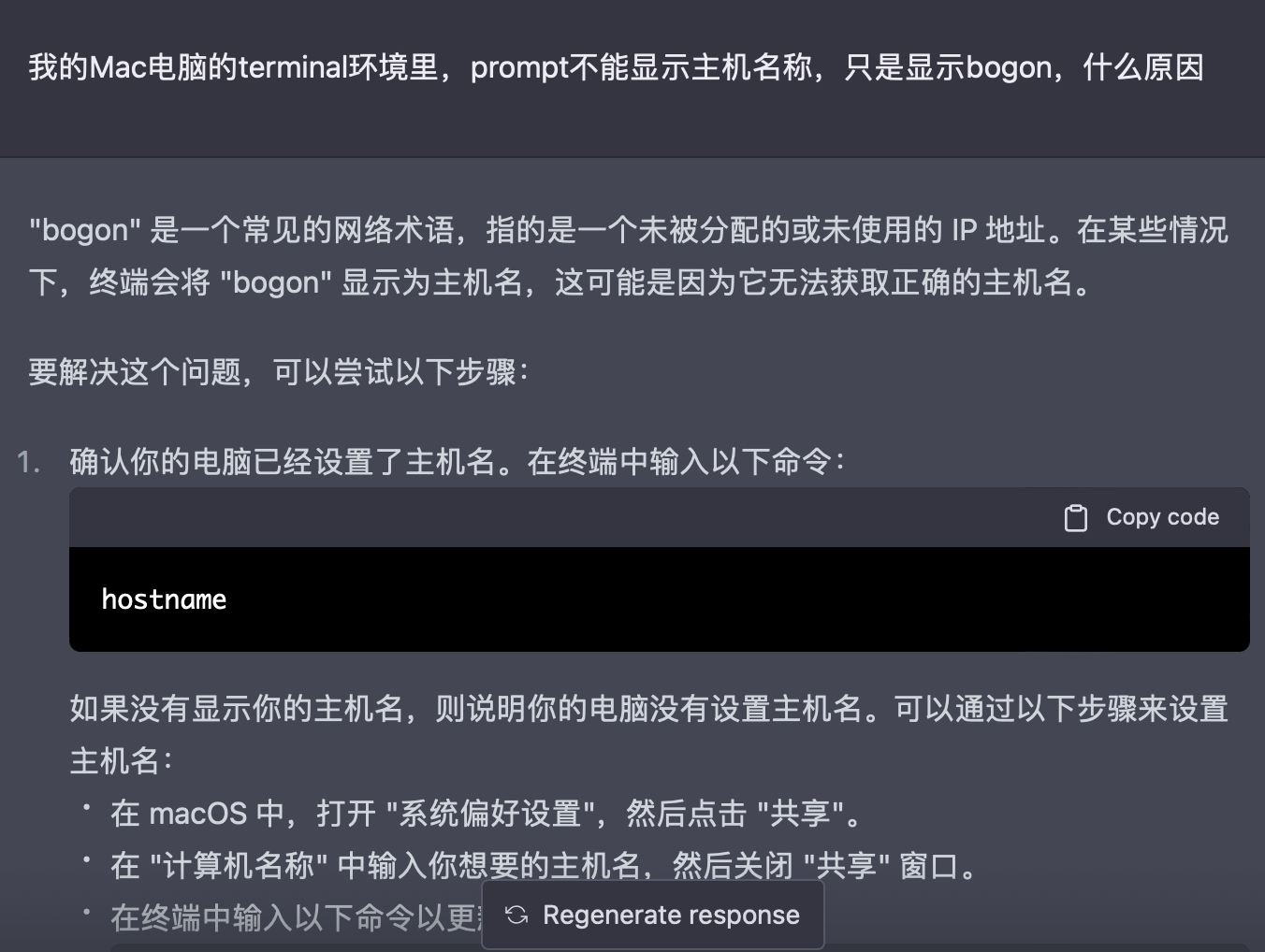
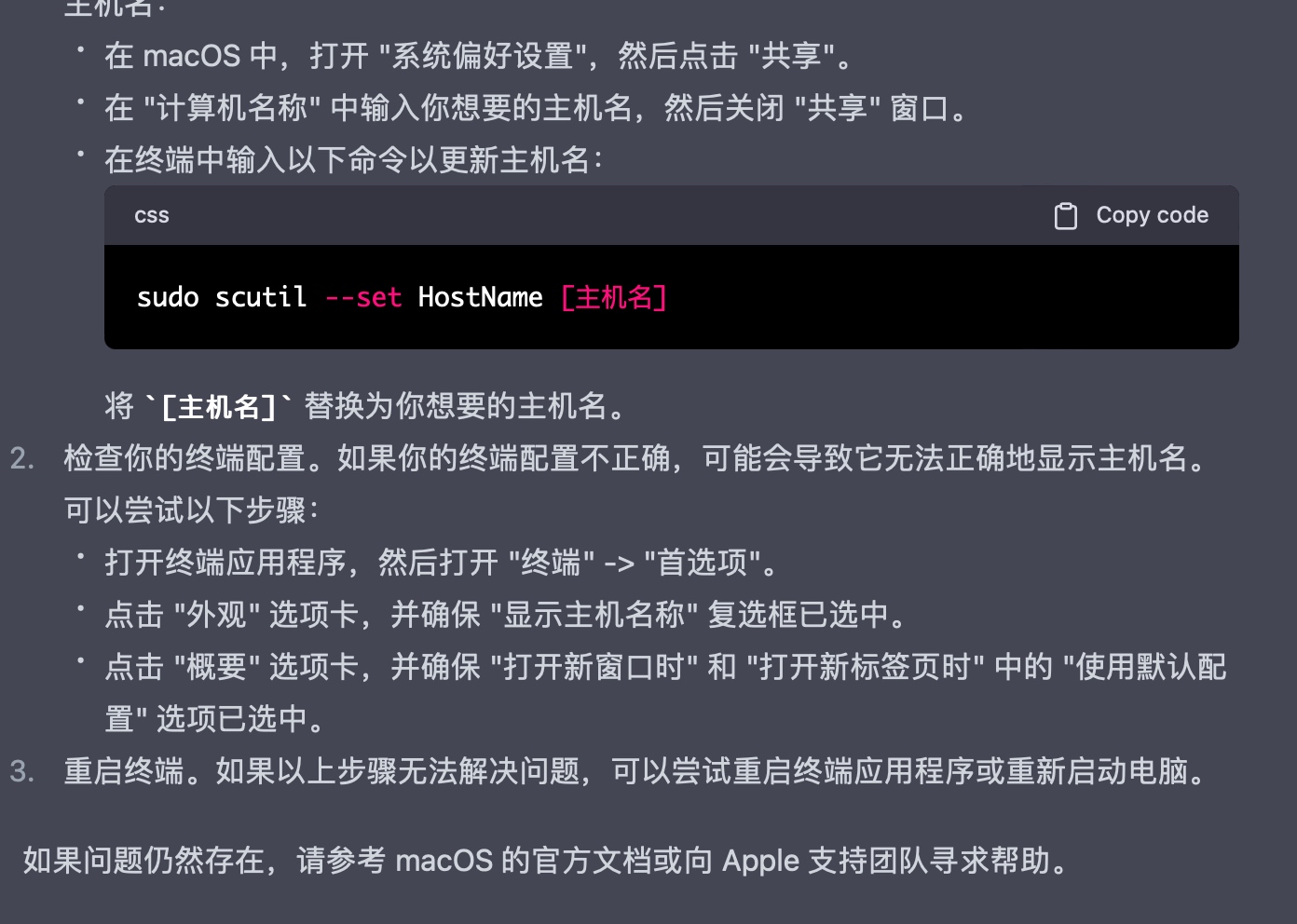
以下是实际操作
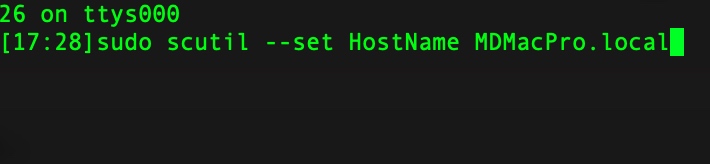
以下是实际操作
西天路上,九九八十一难,唐僧四人遭遇的各种妖魔鬼怪,每个章节结束,都发现不过是天上各路神仙的小号而已。
要解决这个问题似乎也不难,放弃取经,各回各家。不过,回家是不是又树立了一个新的目标,回家路上是不是也会有新的妖怪出现?
似乎,只要心有所念,必定会有配套的烦恼涌现。
最近迷上了chatGPT,逐渐得出一个结论,你使用chatGPT的效果,其实就是你和这个数字世界的边界,或者你和这个数字世界的熟悉程度。
例如
我越来越相信高斯分布,这个世界虽然很大,钟型曲线包裹下的芸芸众生,差异其实很小。而一旦你发现自己和长尾集合中的某个现象有了交集,一定不要犹豫、不要懒惰,要努力抓着它,这是让你摆脱中轴线的唯一机会。
2019年第一次听JJ介绍大模型的时候,除了惊奇外,没有多少想法,毕竟所需要的储备知识近乎于无,而且没有任何应用场景。虽然随后的几年,自己隐隐约约觉得,AI技术是真正的工具,使用这个工具,我可以更好的认识世界、认识自己,就像小时候利用脚蹼进行自由泳的练习一样。
中间几年无非疫情、各种无关紧要的政府项目,JJ也离职去开创自己的事业,虽然短短1年多,我从他这里没有学习到任何核心技术,但是这种人与人的差距,深深影响了我对高斯分布的看法。
终于,chatGPT来了,我梦寐以求的工具,竟然以这么戏剧化的方式将临身边。
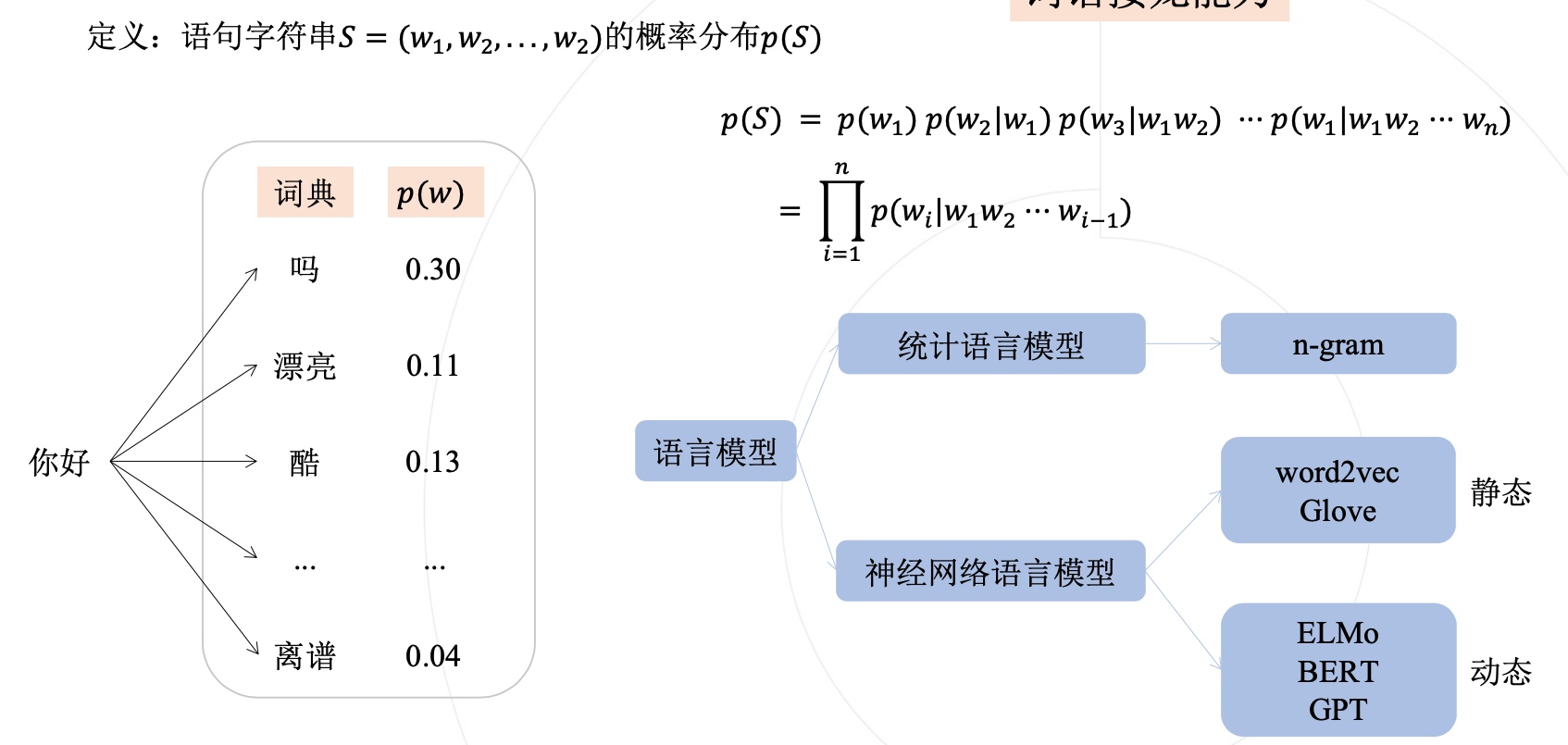
语句字符串S,就是一个句子,它的概率分布,可以是每个单词在这句话中出现的概率。
𝑝(𝑆) = 𝑝(𝑤1) 𝑝(𝑤2|𝑤1) 𝑝(𝑤3|𝑤1𝑤2) ··· 𝑝(𝑤1|𝑤1𝑤2 ··· 𝑤n)
公式的第一行,是将句子的概率分解为每个单词的条件概率相乘的形式, 例如,p(w2|w1)表示给定w1出现后,w2出现的概率。按照这样的方式,我们可以得到整个句子的概率分布。
总体来说,这个公式展示了语言模型如何基于先前的单词或文本序列,计算出下一个单词出现的概率,并进而计算整个句子的概率分布。
"I"出现了1次
"love"出现了1次
"to"出现了1次
"eat"出现了1次
"pizza"出现了1次
最后,我们可以计算每个单词在字符串S中出现的概率,如下所示:
P(“I”) = 1/5 = 0.2
P(“love”) = 1/5 = 0.2
P(“to”) = 1/5 = 0.2
P(“eat”) = 1/5 = 0.2
P(“pizza”) = 1/5 = 0.2
这个概率分布可以用于各种自然语言处理任务,例如语言模型、机器翻译和文本分类等。
大模型训练时,面对海量数据,没法承担高昂的标注成本,往往会采用自监督学习的方式。
自监督学习是一种无监督学习的方法,它通过利用数据的某些属性来设置伪监督任务来替换标准监督任务,从而使模型能够从大量未标记的数据中进行训练。
自监督学习的目标是学习到数据的有用表示,这些表示可以用于各种任务,例如分类、检测、分割和生成等。
自监督学习的一个例子是对于“损失函数中使用到的监督信息无需人工标注”的训练范式的一种统称,自监督学习可以用在预训练上,也可以用在实际任务本身的训练上,当然目前看来还是用在预训练上的情况显著更多.
Transformer摆脱了人工标注数据集的缺陷,模型在质量上更优、 更易于并行化,所需训练时间明显更少,
Transformer通过成功地将其应用于具有大量和有限训练数据的分析,可以很好地推广到其他任务。
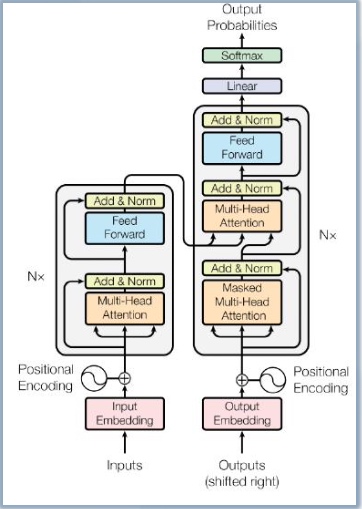
Transformer模型架构如下图