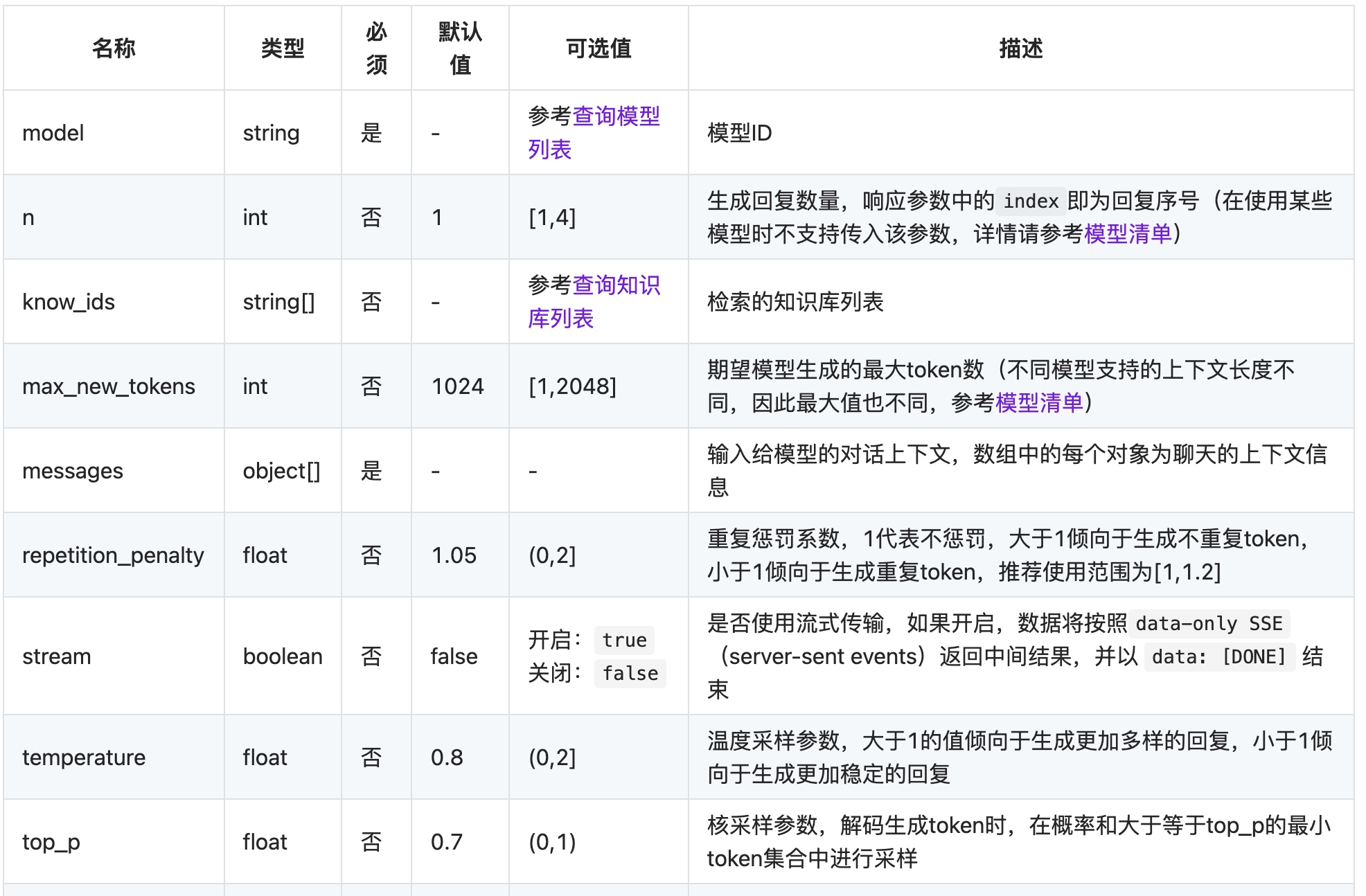
这是商汤sensennova大语言模型的示例代码(对话生成_无对话历史)
stream = True # 流式输出或非流式输出
model_id = "nova-ptc-xl-v1" # 填写真实的模型ID
resp = sensenova.ChatCompletion.create(
messages=[{"role": "user", "content": "人生天地间,下一句是啥"}],
model=model_id,
stream=stream,
max_new_tokens=1024,
n=1,
repetition_penalty=1.05,
temperature=0.9,
top_p=0.7,
know_ids=[],
user="sensenova-python-test-user",
knowledge_config={
"control_level": "normal",
"knowledge_base_result": True,
"knowledge_base_configs":[]
},
plugins={
"associated_knowledge": {
"content": "需要注入给模型的知识",
"mode": "concatenate"
},
"web_search": {
"search_enable": True,
"result_enable": True
},
}
)
if not stream:
resp = [resp]
for part in resp:
choices = part['data']["choices"]
for c_idx, c in enumerate(choices):
if len(choices) > 1:
sys.stdout.write("===== Chat Completion {} =====\n".format(c_idx))
if stream:
delta = c.get("delta")
if delta:
sys.stdout.write(delta)
else:
sys.stdout.write(c["message"])
if len(choices) > 1:
sys.stdout.write("\n")
sys.stdout.flush()
下面我们来line by line的解释
英文
- stream = True: This line sets a variable named stream. If True, it indicates that the output will be in a streaming fashion. Streaming output is typically used for real-time data processing.
- model_id = "nova-ptc-xl-v1": Here, model_id is set to the string "nova-ptc-xl-v1", which seems to be the identifier of a specific model in the Sensenova framework.
- resp = sensenova.ChatCompletion.create(…): This line calls the create method of the ChatCompletion class from the sensenova module. This method likely generates a chat completion or response based on the given parameters.
- messages=[{"role": "user", "content": "人生天地间,下一句是啥"}]: Specifies the input message for the chat model. Here, the role is set as "user" and the content is a Chinese phrase.
- model=model_id: Specifies the model to be used for chat completion.
- stream=stream: Passes the stream variable to control streaming behavior.
- max_new_tokens=1024: Limits the number of new tokens (words/characters) that the model can generate.
- n=1: Indicates that the number of completions to generate is 1.
- repetition_penalty=1.05: Adjusts the likelihood of the model repeating the same line.
- temperature=0.9: Sets the creativity or randomness of the response.
- top_p=0.7: Controls the diversity of the response.
- know_ids=[]: An empty list, possibly for specifying known IDs for context or tracking.
- user="sensenova-python-test-user": Specifies a user identifier.
- knowledge_config={…}: Configures how the model should use external knowledge.
- plugins={…}: Configures additional features or plugins, like injecting knowledge (associated_knowledge) and enabling web search (web_search).
- if not stream: resp = [resp]: If stream is False, this wraps resp in a list. This is probably for consistency in processing the response whether it’s streaming or not.
- for part in resp:: Iterates over each part in the response.
- choices = part[‘data’]["choices"]: Extracts the choices from the response data. This might contain the actual chat completions or responses.
- for c_idx, c in enumerate(choices):: Iterates over the choices, with c_idx being the index and c being the content.
- if len(choices) > 1: …: If there are multiple choices, it prints a separator with the index.
- Inside the nested if and else:
- If stream is True, it prints delta from each choice, which might be a part of the streaming response.
- If stream is False, it prints the message from each choice.
- sys.stdout.flush(): Ensures that everything written to the standard output is actually displayed. This is often used in streaming or real-time applications to update the output promptly.
This code seems to be a part of a chatbot implementation using the Sensenova framework, where it sends a message to a chat model and processes the response, either in a streaming manner or as a complete response.
中文
- stream = True:这行代码设置了一个名为 stream 的变量。如果为 True,表示输出将以流式方式进行。流式输出通常用于实时数据处理。
- model_id = "nova-ptc-xl-v1":这里,model_id 被设置为字符串 "nova-ptc-xl-v1",这似乎是 Sensenova 框架中特定模型的标识符。
- resp = sensenova.ChatCompletion.create(…):这行代码调用了 sensenova 模块中 ChatCompletion 类的 create 方法。这个方法可能会根据给定的参数生成聊天回复。
- messages=[{"role": "user", "content": "人生天地间,下一句是啥"}]:指定了聊天模型的输入消息。这里,角色被设置为 "user",内容是一个中文短语。
- model=model_id:指定用于聊天完成的模型。
- stream=stream:传递 stream 变量以控制流式行为。
- max_new_tokens=1024:限制模型可以生成的新令牌(单词/字符)的数量。
- n=1:表示要生成的完成次数为 1。
- repetition_penalty=1.05:调整模型重复相同行的可能性。
- temperature=0.9:设置回应的创造性或随机性。
- top_p=0.7:控制回应的多样性。
- know_ids=[]:一个空列表,可能用于指定上下文或跟踪的已知 ID。
- user="sensenova-python-test-user":指定用户标识符。
- knowledge_config={…}:配置模型如何使用外部知识。
- plugins={…}:配置额外的功能或插件,如注入知识(associated_knowledge)和启用网络搜索(web_search)。
- if not stream: resp = [resp]:如果 stream 为 False,则将 resp 包装在列表中。这可能是为了无论是否流式,处理响应时的一致性。
- for part in resp::遍历响应中的每个部分。
- choices = part[‘data’]["choices"]:从响应数据中提取 choices。这可能包含实际的聊天完成或响应。
- for c_idx, c in enumerate(choices)::遍历 choices,c_idx 为索引,c 为内容。
- if len(choices) > 1: …:如果有多个选项,它将打印一个分隔符和索引。
- 在嵌套的 if 和 else 中:
- 如果 stream 为 True,它会打印每个选项中的 delta,这可能是流式响应的一部分。
- 如果 stream 为 False,它会打印每个选项中的 message。
- sys.stdout.flush():确保写入标准输出的所有内容实际上都被显示。这在流式或实时应用中经常用于及时更新输出。
这段代码似乎是使用 Sensenova 框架的聊天机器人实现的一部分,其中它发送消息到聊天模型并处理响应,无论是以流式方式还是作为完整的响应。
核采样参数
top_p:核采样参数,用于解码生成token的过程。
“核采样参数,解码生成token时,在概率和大于等于top_p的最小token集合中进行采样”这句话描述的是一种称为“核采样”(Top-p sampling)的机制,它用于生成语言模型的回复。下面是这个概念的详细解释:
核采样(Top-p sampling):这是一种在自然语言处理中用于生成文本的技术。在生成下一个词(token)时,核采样只考虑那些累积概率和达到指定阈值 top_p 的最可能的词。 解码生成token:当语言模型生成回复时,它逐个生成词(token)。解码过程是选择每个步骤中应该生成哪个词的过程。 在概率和大于等于top_p的最小token集合中进行采样:这意味着在生成每个词时,模型会查看所有可能的下一个词及其概率。然后,它计算这些概率的累积和,并选择一个累积和至少为 top_p 的词的集合。模型仅从这个集合中随机选择下一个词,而不是从所有可能的词中选择。 举例来说,如果 top_p 设为0.7,模型会考虑累积概率和至少达到70%的那部分词。这样的选择过程确保了生成的文本既有一定的多样性(因为不总是选择最可能的词),同时也保持了一定的连贯性和可读性。 核采样是一种平衡生成文本多样性和可预测性的有效方法,常用于各种基于深度学习的语言生成模型。