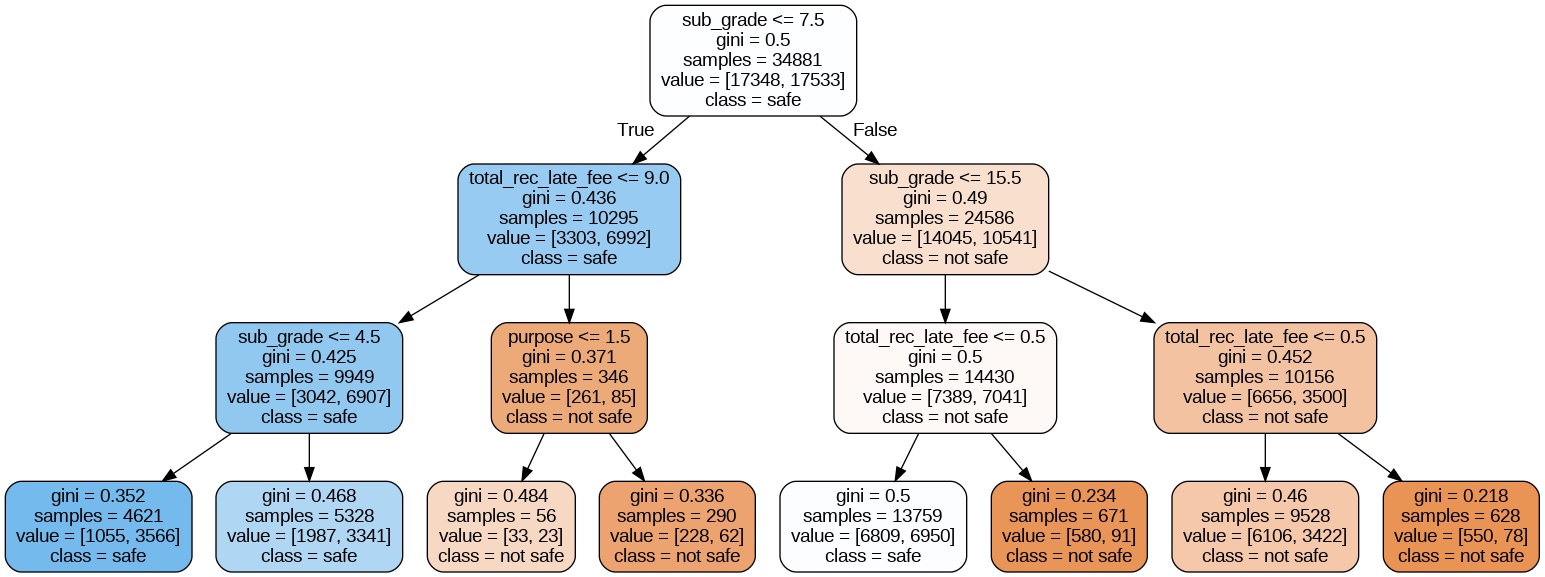
使用colab进行【中文分词模型测试】,编程环境自动给出了train_test_spint函数的提示,我对于这种提示不太清楚,就让chatgpt来解释。
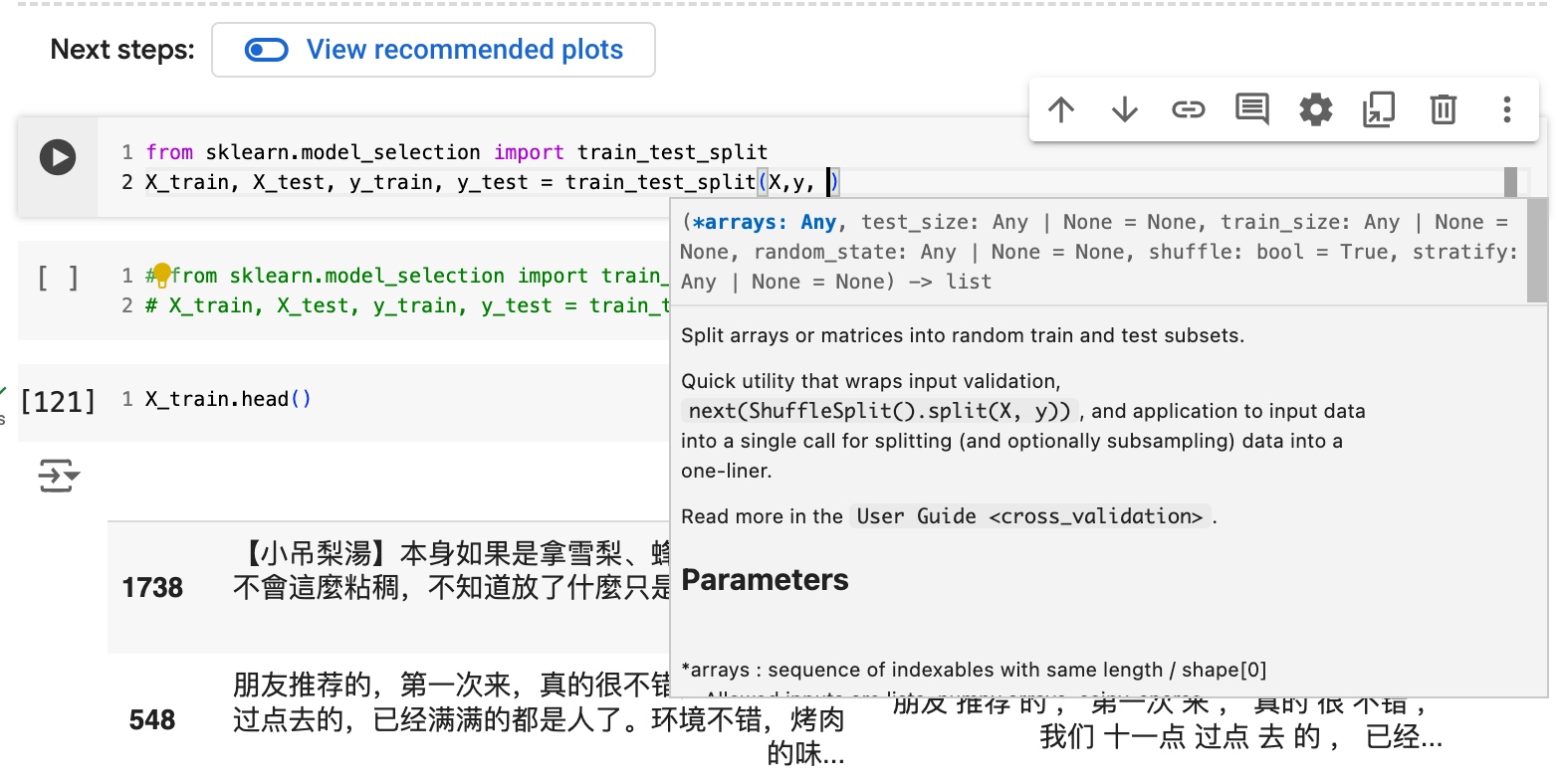
请chatgpt第一次解释

The image you uploaded shows the function signature and description for a function used to split arrays or matrices into random train and test subsets. This function is likely train_test_split from the sklearn.model_selection module in the scikit-learn library. Here’s a breakdown of the parameters and how to use them:
Function Signature
python
Copy code
(*arrays: Any, test_size: Any | None = None, train_size: Any | None = None, random_state: Any | None = None, shuffle: bool = True, stratify: Any | None = None) -> list
Description
Purpose: The function splits arrays or matrices into random train and test subsets.
Usage: It wraps input validation and application to input data into a single call for splitting (and optionally subsampling) data into a one-liner.
Parameters
*arrays: Sequence of indexables with the same length/shape[0]. This is where you pass the data you want to split. It can be features (X) and labels (y).
test_size: The proportion of the dataset to include in the test split. Can be a float (e.g., 0.25 for 25% test data), an integer (number of samples), or None (in which case the value is set to the complement of the train size).
train_size: The proportion of the dataset to include in the train split. Can be a float, an integer, or None (in which case the value is automatically set to the complement of the test size).
random_state: Controls the shuffling applied to the data before splitting. Pass an integer for reproducible output across multiple function calls.
shuffle: Whether or not to shuffle the data before splitting. Default is True.
stratify: If not None, data is split in a stratified fashion, using this as the class labels.
请chatgpt第二次解释
I understand that the concept can be a bit confusing, so let me clarify it further.
The random_state parameter in functions like train_test_split controls the randomness of the operation. It ensures that the random processes involved (such as shuffling the data) are repeatable. By setting random_state to a specific value, you ensure that the split will be the same each time you run the code, as long as the data and the code remain unchanged.
Here’s a step-by-step explanation and demonstration:
-
What does random_state do?
random_state sets the seed for the random number generator. Different seeds will produce different sequences of random numbers, and therefore different shuffles and splits of the data.
-
Why does it matter?
- Using the same
random_state value allows you to reproduce your results exactly. This is useful for debugging, sharing your results with others, and ensuring consistent results when rerunning experiments.
-
Different values for random_state:
- Different
random_state values will initialize the random number generator differently, leading to different shuffles of the data and, consequently, different splits.
Demonstration
Let’s demonstrate this with a simple example using train_test_split with different random_state values.
Using random_state=1
from sklearn.model_selection import train_test_split
# Sample data
X = [[1, 2], [3, 4], [5, 6], [7, 8]]
y = [0, 1, 0, 1]
# Split the data with random_state=1
X_train_1, X_test_1, y_train_1, y_test_1 = train_test_split(X, y, test_size=0.25, random_state=1)
print("random_state=1")
print("X_train:", X_train_1)
print("X_test:", X_test_1)
print("y_train:", y_train_1)
print("y_test:", y_test_1)
Using random_state=42
# Split the data with random_state=42
X_train_42, X_test_42, y_train_42, y_test_42 = train_test_split(X, y, test_size=0.25, random_state=42)
print("\nrandom_state=42")
print("X_train:", X_train_42)
print("X_test:", X_test_42)
print("y_train:", y_train_42)
print("y_test:", y_test_42)
Expected Output
For random_state=1
random_state=1
X_train: [[5, 6], [1, 2], [7, 8]]
X_test: [[3, 4]]
y_train: [0, 0, 1]
y_test: [1]
For random_state=42
random_state=42
X_train: [[7, 8], [3, 4], [1, 2]]
X_test: [[5, 6]]
y_train: [1, 1, 0]
y_test: [0]
As you can see, using random_state=1 and random_state=42 results in different splits of the data. This is because the random number generator is initialized differently with each value, resulting in different shuffling of the data before it is split.
Consistency Across Runs
If you run the above code multiple times with the same random_state value, you will get the same split every time. However, changing the random_state value will change the split.
Running Multiple Times for the Same random_state
To verify this, you can run the split multiple times with the same random_state:
for i in range(3):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
print(f"Run {i+1}:")
print("X_train:", X_train)
print("X_test:", X_test)
print("y_train:", y_train)
print("y_test:", y_test)
print("-" * 30)
Expected Output for Each Run with random_state=42
Run 1:
X_train: [[7, 8], [3, 4], [1, 2]]
X_test: [[5, 6]]
y_train: [1, 1, 0]
y_test: [0]
------------------------------
Run 2:
X_train: [[7, 8], [3, 4], [1, 2]]
X_test: [[5, 6]]
y_train: [1, 1, 0]
y_test: [0]
------------------------------
Run 3:
X_train: [[7, 8], [3, 4], [1, 2]]
X_test: [[5, 6]]
y_train: [1, 1, 0]
y_test: [0]
------------------------------
This demonstrates that the split is consistent across multiple runs with the same random_state. Changing the random_state value will produce a different but consistent split for that specific value.