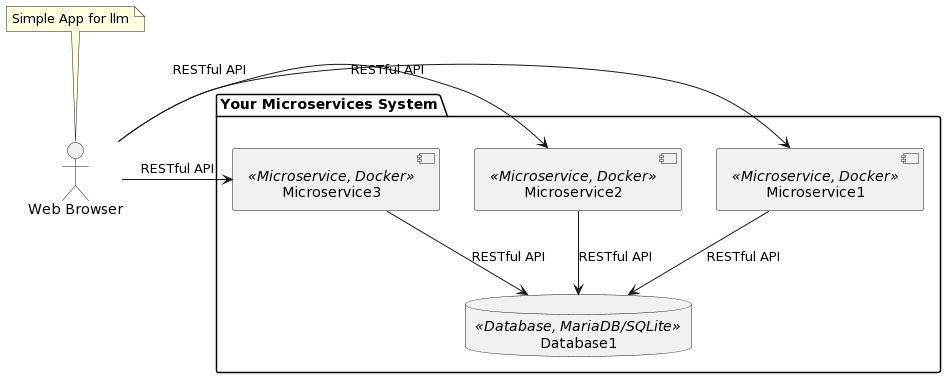
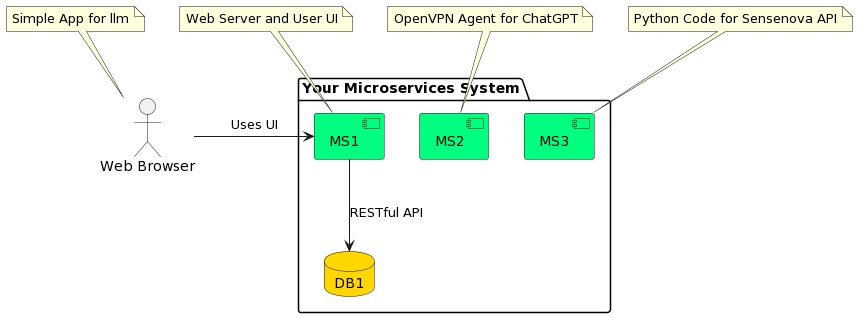
方案一
下面是在 Linux 服务器上配置 OpenVPN 客户端、设置路由以及保证应用通过 VPN 隧道访问 ChatGPT API 的一般步骤和命令。请注意,在进行以下操作之前,请确保您拥有阿里云服务器的 root 权限或 sudo 权限,以及加拿大 OpenVPN 服务器的必要配置文件。
步骤 1: 安装 OpenVPN 客户端
在您的阿里云服务器上安装 OpenVPN 客户端:
sudo apt-get update # 如果是基于 Debian 的系统
sudo apt-get install openvpn
或者
sudo yum update # 如果是基于 RHEL 的系统
sudo yum install openvpn
步骤 2: 配置 OpenVPN 客户端
将从加拿大 OpenVPN 服务器获取的配置文件(通常是 .ovpn 文件)传输到阿里云服务器。
启动 OpenVPN 客户端,连接到服务器:
sudo openvpn --config /path/to/your/vpnconfig.ovpn
确保将 /path/to/your/vpnconfig.ovpn 替换为您的实际配置文件路径。这条命令将启动 OpenVPN 并尝试连接到您的加拿大 VPN 服务器。
步骤 3: 路由设置
修改 OpenVPN 配置文件以添加路由。打开 .ovpn 文件,添加类似以下行来指定路由:
route ChatGPT_API_IP 255.255.255.255 vpn_gateway
将 ChatGPT_API_IP 替换为 ChatGPT API 的实际 IP 地址,vpn_gateway 通常会自动设置为通过 VPN 连接的默认网关。
或者,您也可以在 OpenVPN 连接后通过命令行手动添加路由:
sudo ip route add ChatGPT_API_IP/32 via VPN_GATEWAY_IP dev tun0
将 ChatGPT_API_IP 替换为 ChatGPT API 的 IP 地址,VPN_GATEWAY_IP 替换为您 VPN 的网关 IP,tun0 是 OpenVPN 使用的默认网络接口,如果您的配置不同,请相应调整。
步骤 4: 验证连接
一旦 OpenVPN 客户端启动并且路由设置完成,您可以使用 ping 命令或类似的网络工具来测试 VPN 连接和路由是否正确:
ping ChatGPT_API_IP
也可以查看路由表确保新路由已经设置:
ip route show
步骤 5: 应用配置
确保您的应用在发起到 ChatGPT API 的请求时,不需要任何特别的配置,因为操作系统的路由表已经指示了通过 VPN 隧道转发到 ChatGPT API 的流量。
步骤 6: 持久化 VPN 连接
为了确保 VPN 连接在服务器重启后自动启动,您可以将 OpenVPN 连接命令添加到系统的启动脚本中,如 rc.local 或使用系统的服务管理器(如 systemd)创建一个服务。
这里的步骤和命令提供了一般的指南,具体的命令可能会根据您的 Linux 发行版和 OpenVPN 配置有所不同。此外,确保您具有连接到 OpenVPN 服务器所需的所有凭据和权限。
方案二
要设置加拿大服务器作为反向代理服务器并转发请求到 ChatGPT API,你可以使用 Nginx 或 Apache。下面以 Nginx 为例,提供详细的配置步骤和命令。
Nginx 反向代理配置
步骤 1: 安装 Nginx
在加拿大的服务器上安装 Nginx:
sudo apt update # 对于 Debian/Ubuntu 系统
sudo apt install nginx
或者对于 RHEL/CentOS 系统
sudo yum update
sudo yum install nginx
步骤 2: 配置 Nginx 作为反向代理
创建一个新的 Nginx 配置文件或编辑现有的站点配置文件:
sudo nano /etc/nginx/sites-available/chatgpt-proxy
在配置文件中添加以下内容:
server {
listen 80;
server_name your-canadian-server.com; # 替换为你加拿大服务器的域名或IP
location / {
proxy_pass https://api.openai.com/v1/; # ChatGPT API 的 URL
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
启用配置并测试:
sudo ln -s /etc/nginx/sites-available/chatgpt-proxy /etc/nginx/sites-enabled/
sudo nginx -t
sudo systemctl restart nginx
步骤 3: 配置 SSL/TLS
使用 Let’s Encrypt 提供的 certbot 工具来自动获取和安装 SSL 证书:
sudo apt install certbot python3-certbot-nginx # 对于 Debian/Ubuntu 系统
或者
sudo yum install certbot python3-certbot-nginx # 对于 RHEL/CentOS 系统
sudo certbot --nginx -d your-canadian-server.com # 用实际域名替换
Certbot 会自动处理证书的获取和安装,并修改 Nginx 配置以启用 HTTPS。
步骤 4: (可选) 设置 API 认证
如果需要,你可以在 Nginx 配置中添加基本认证:
location / {
# ...其他配置保持不变...
auth_basic "Restricted Content";
auth_basic_user_file /etc/nginx/.htpasswd; # 路径到密码文件
}
创建密码文件并设置用户和密码:
sudo apt-get install apache2-utils # 安装 htpasswd 工具
sudo htpasswd -c /etc/nginx/.htpasswd username # 用实际用户名替换
步骤 5: 修改阿里云应用配置
在阿里云服务器上的应用中,你需要将所有指向 ChatGPT API 的请求修改为通过你的加拿大服务器反向代理的 URL。
例如,如果你的加拿大服务器域名是 your-canadian-server.com,应用中的 API 请求 URL 应更改为:
https://your-canadian-server.com/v1/... # 具体路径根据实际请求调整
注意事项
确保在配置 Nginx 或应用时替换所有的占位符(如 your-canadian-server.com 和 username)为实际的值。
使用 SSL/TLS 时,确保你的域名已正确解析到加拿大服务器的 IP 地址,并且端口 80 和 443 在服务器上是开放的。
测试配置更改后的应用以确保它可以通过加拿大服务器正确访问 ChatGPT API
方案三
要通过 SSH 隧道来转发请求到 ChatGPT API,你需要在阿里云服务器上执行以下步骤:
步骤 1: 建立 SSH 隧道
在阿里云服务器上,使用 SSH 命令建立一个隧道。这个隧道将本地端口转发到加拿大服务器上的端口,然后由加拿大服务器转发到 ChatGPT API。
执行以下命令以建立隧道:
ssh -L [本地端口]:api.openai.com:443 [用户]@[加拿大服务器IP] -N -f
[本地端口]:这是阿里云服务器上的本地端口号,选择一个未被使用的端口,例如 8080。
api.openai.com:443:这是 ChatGPT API 的域名和端口。
[用户]:这是你在加拿大服务器上的用户名。
[加拿大服务器IP]:这是加拿大服务器的公网 IP 地址。
-N 告诉 SSH 客户端不执行远程命令,只进行端口转发。
-f 告诉 SSH 客户端在后台运行。
例如:
ssh -L 8080:api.openai.com:443 myuser@198.51.100.0 -N -f
这条命令将在后台创建一个 SSH 隧道,把阿里云服务器上的 8080 端口的流量转发到 api.openai.com 的 443 端口上。
步骤 2: 测试端口转发
测试本地端口转发是否工作正常:
curl -v https://localhost:8080/v1/engines -H "Authorization: Bearer YOUR_OPENAI_API_KEY"
这个命令应该返回 ChatGPT API 的响应。确保将 YOUR_OPENAI_API_KEY 替换为你的实际 OpenAI API 密钥。
步骤 3: 修改应用配置
修改你在阿里云服务器上的应用配置,把所有指向 ChatGPT API 的请求改为通过本地端口:
https://localhost:8080/v1/...
这样,当你的应用尝试连接到 ChatGPT API 时,实际上它将通过 SSH 隧道发送请求。
注意事项
请确保你的阿里云服务器上的防火墙配置允许本地端口(例如 8080)的流量。
你可能需要在加拿大服务器上配置 SSH 以允许端口转发。
在生产环境中使用 SSH 隧道时,可能需要考虑使用更稳健的方法来保持隧道的持续运行,如使用 autossh。
由于使用了 -f 参数,SSH 命令会在后台运行。如果需要终止隧道,你可以找到对应的 SSH 进程并杀掉它,或者关闭监听本地端口的 SSH 隧道。