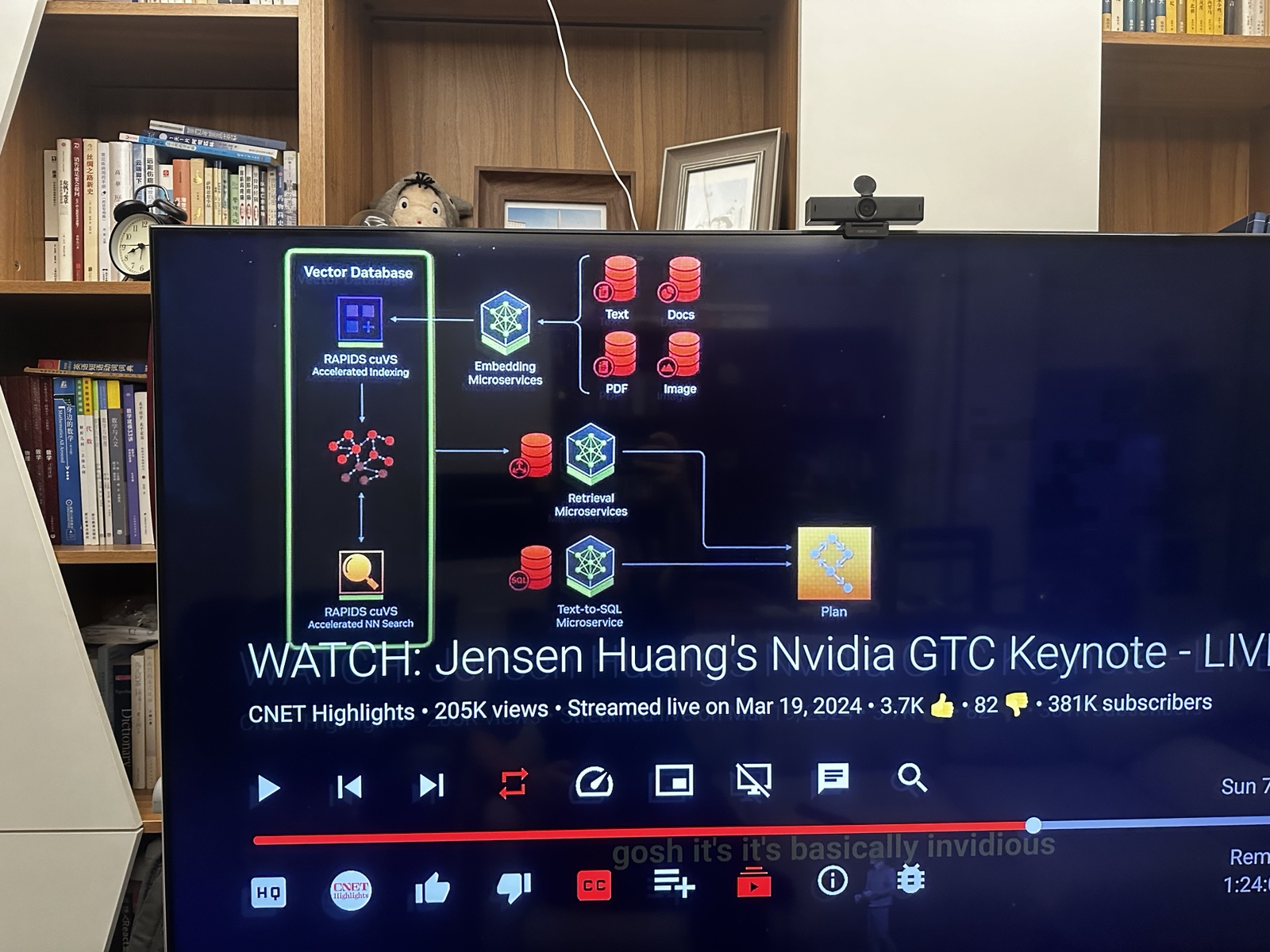
CPU服务器
对比这两组服务器的规格,我们可以从性能、功能和适用场景等角度进行分析:
CPU性能
第一组服务器:
CPU设计为单一Die,有助于降低内部延迟,提高处理效率。
每颗CPU拥有至少28核心,主频达到2.6GHz,缓存容量至少42MB。
支持AVX512指令集,适合进行高强度的计算任务,如科学计算和工程模拟。
国产设备:
每颗CPU核心数至少32核,主频2.2GHz,缓存容量至少64MB,高于第一组服务器。
支持8个DDR4内存通道,相当于第一组服务器。
分析:国产设备的CPU在核心数量和缓存容量上优于第一组服务器,但主频略低,可能影响单核任务的执行效率。
内存配置
第一组服务器:
至少4条内存,每条32GB,频率3200MHz,支持ECC校验。
国产设备:
至少8条内存,同样的容量和频率,支持ECC校验。
分析:国产设备在内存数量上更具优势,这可能对运行大规模数据库或内存密集型应用更有利。
存储配置
第一组服务器:
系统盘:≥960GB SSD,SATA接口。
数据盘:PCIe 4.0接口,≥3.84TB SSD,连续读取速率≥6500MB/s。
国产设备:
系统盘:≥480GB SSD,SATA接口。
数据盘:SATA接口,≥1.92TB SSD。
分析:第一组服务器的数据盘具有更高的存储容量和显著更快的读取速率,更适合需求高速数据处理的场景,如高性能计算和大数据分析。
网络和阵列卡
两组服务器在网络配置相同:均配备双光口万兆网卡,支持bond0,适合高速网络环境。
阵列卡:
第一组服务器阵列卡缓存1G以上。
国产设备阵列卡缓存2G以上,更有利于大规模数据处理和缓冲。
适用场景:
第一组服务器:适合需要高计算性能和高速数据访问的应用,如科学研究、图形渲染和金融模型计算。
国产设备:由于其更多的内存和更大的阵列卡缓存,更适合数据密集型任务和大规模多任务处理,例如云服务和大型企业级应用。
综合来看,两组服务器各有优势,具体选择应根据实际需求和预算考虑。国产设备在内存和缓存方面的优势可能为特定用途提供了更好的性价比。
GPU服务器
继续对比这两组服务器的规格,我们可以深入分析它们的性能、功能以及潜在的适用场景:
CPU性能
第一组服务器与第二组服务器在CPU规格上基本一致:
都配备了两颗CPU,每颗CPU核心数至少24核,主频至少2.2GHz,缓存至少64MB。
这种配置提供了均衡的多核和单核处理能力,适合广泛的应用。
内存配置
内存规格完全一致:
两组服务器都配置有8条32GB DDR4内存,频率3200MHz,支持ECC校验。
这样的内存配置可以有效支持大规模数据处理和复杂的计算需求。
GPU配置
第一组服务器:
搭载8张H800 GPU,但未详述其性能规格。
第二组服务器:
明确要求整机算力不低于768 TFlops的半精度算力,显存总量不低于128GB,显存带宽不低于800GB/s,支持高带宽的卡间互连(不低于192GB/s)。
这样的GPU配置非常适合于高性能计算、深度学习和复杂的图形处理。
存储配置
系统盘和数据盘:
两组服务器在系统盘和数据盘的配置上几乎相同,均为SATA接口SSD,系统盘≥480GB,数据盘容量≥1.92TB。
网络和阵列卡
网络配置相同:
均配备双光口万兆网卡,支持bond0,确保高速稳定的网络连接。
阵列卡配置略有差异:
第一组服务器阵列卡缓存1G以上。
第二组服务器阵列卡缓存2G以上,对于需要高速数据写入和读取的应用来说,更大的缓存可以提供更好的性能。
适用场景
第一组服务器:
由于未详细描述GPU性能,这组服务器可能适合通用的数据中心应用,如虚拟化、数据库管理和中等规模的计算需求。
第二组服务器:
明确的高性能GPU配置使其非常适合于AI训练、科学计算和任何需要大规模并行处理的场景。
综上,第二组服务器在GPU性能上明显优于第一组,特别是在处理高负载的计算密集型任务时。这种配置的机器特别适用于需要高度计算资源的专业领域,例如人工智能、模拟和高性能计算(HPC)领域。
奇怪的问题
chatGPT4 付费版本,似乎没法通过网络搜索获得H800这个阉割版的具体数据,而kimi则展现了灵活务实的一面,给出下面的回答
来自kimi的回答
根据搜索结果中的信息,H800 GPU 的具体半精度算力(FP16)没有直接给出。然而,从搜索结果中我们可以推断一些相关信息。在该搜索结果中提到,H800 的算力水平约等于 A100 的 50% 和 H100 的 15%。由于 H100 GPU 在 FP16 精度下的算力是 4 petaflops,我们可以据此推算 H800 GPU 的大致半精度算力。
如果 H800 的算力是 H100 的 15%,那么 H800 的 FP16 算力将是:
\[ 4 \text{ petaflops} \times 0.15 = 0.6 \text{ petaflops} \]
即 H800 GPU 的半精度算力大约是 0.6 petaflops。请注意,这是一个基于现有信息推算的结果,并非直接从搜索结果中得到的具体数值。