以下是实际操作
以下是实际操作
最近迷上了chatGPT,逐渐得出一个结论,你使用chatGPT的效果,其实就是你和这个数字世界的边界,或者你和这个数字世界的熟悉程度。
例如
我越来越相信高斯分布,这个世界虽然很大,钟型曲线包裹下的芸芸众生,差异其实很小。而一旦你发现自己和长尾集合中的某个现象有了交集,一定不要犹豫、不要懒惰,要努力抓着它,这是让你摆脱中轴线的唯一机会。
2019年第一次听JJ介绍大模型的时候,除了惊奇外,没有多少想法,毕竟所需要的储备知识近乎于无,而且没有任何应用场景。虽然随后的几年,自己隐隐约约觉得,AI技术是真正的工具,使用这个工具,我可以更好的认识世界、认识自己,就像小时候利用脚蹼进行自由泳的练习一样。
中间几年无非疫情、各种无关紧要的政府项目,JJ也离职去开创自己的事业,虽然短短1年多,我从他这里没有学习到任何核心技术,但是这种人与人的差距,深深影响了我对高斯分布的看法。
终于,chatGPT来了,我梦寐以求的工具,竟然以这么戏剧化的方式将临身边。
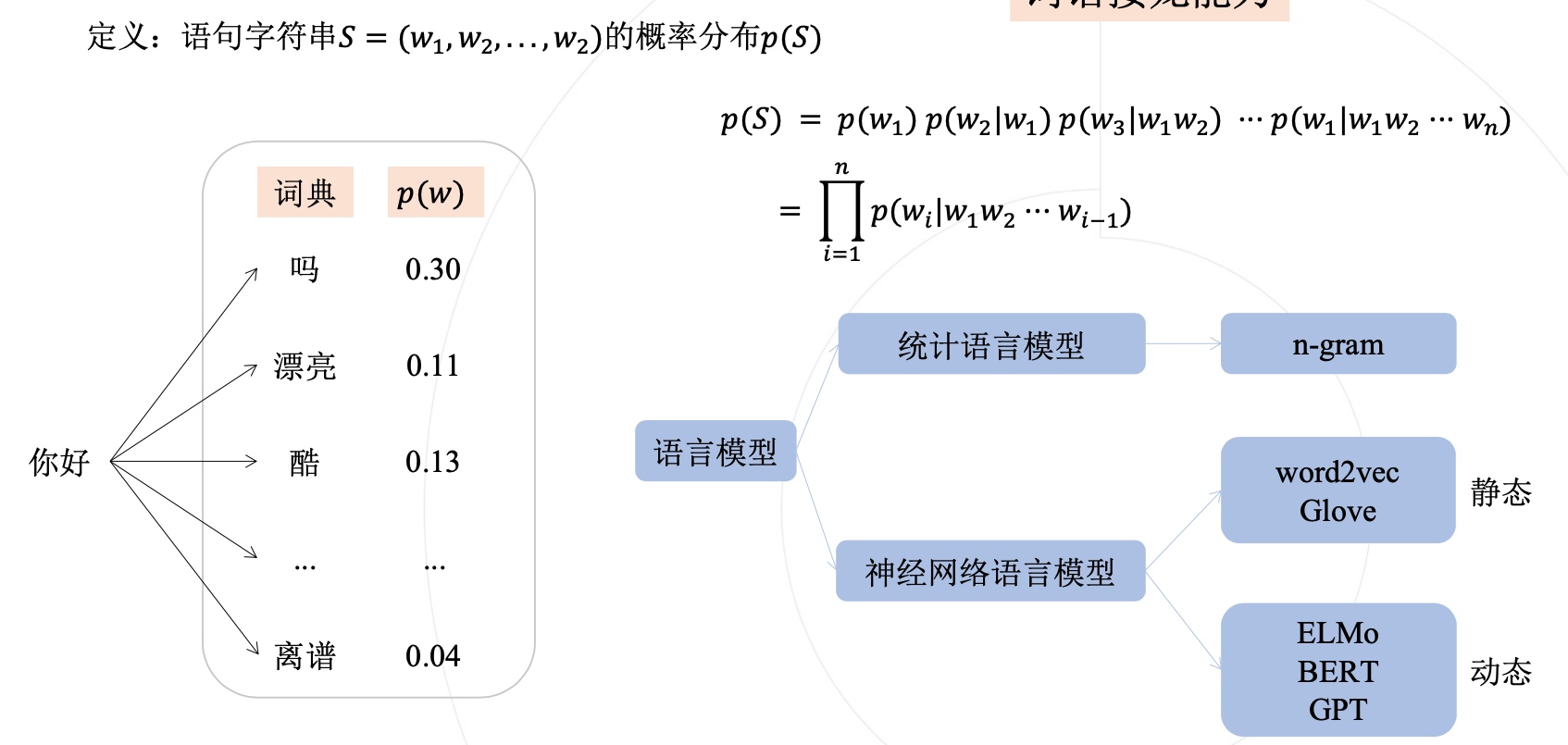
语句字符串S,就是一个句子,它的概率分布,可以是每个单词在这句话中出现的概率。
𝑝(𝑆) = 𝑝(𝑤1) 𝑝(𝑤2|𝑤1) 𝑝(𝑤3|𝑤1𝑤2) ··· 𝑝(𝑤1|𝑤1𝑤2 ··· 𝑤n)
公式的第一行,是将句子的概率分解为每个单词的条件概率相乘的形式, 例如,p(w2|w1)表示给定w1出现后,w2出现的概率。按照这样的方式,我们可以得到整个句子的概率分布。
总体来说,这个公式展示了语言模型如何基于先前的单词或文本序列,计算出下一个单词出现的概率,并进而计算整个句子的概率分布。
"I"出现了1次
"love"出现了1次
"to"出现了1次
"eat"出现了1次
"pizza"出现了1次
最后,我们可以计算每个单词在字符串S中出现的概率,如下所示:
P(“I”) = 1/5 = 0.2
P(“love”) = 1/5 = 0.2
P(“to”) = 1/5 = 0.2
P(“eat”) = 1/5 = 0.2
P(“pizza”) = 1/5 = 0.2
这个概率分布可以用于各种自然语言处理任务,例如语言模型、机器翻译和文本分类等。
大模型训练时,面对海量数据,没法承担高昂的标注成本,往往会采用自监督学习的方式。
自监督学习是一种无监督学习的方法,它通过利用数据的某些属性来设置伪监督任务来替换标准监督任务,从而使模型能够从大量未标记的数据中进行训练。
自监督学习的目标是学习到数据的有用表示,这些表示可以用于各种任务,例如分类、检测、分割和生成等。
自监督学习的一个例子是对于“损失函数中使用到的监督信息无需人工标注”的训练范式的一种统称,自监督学习可以用在预训练上,也可以用在实际任务本身的训练上,当然目前看来还是用在预训练上的情况显著更多.
Transformer摆脱了人工标注数据集的缺陷,模型在质量上更优、 更易于并行化,所需训练时间明显更少,
Transformer通过成功地将其应用于具有大量和有限训练数据的分析,可以很好地推广到其他任务。
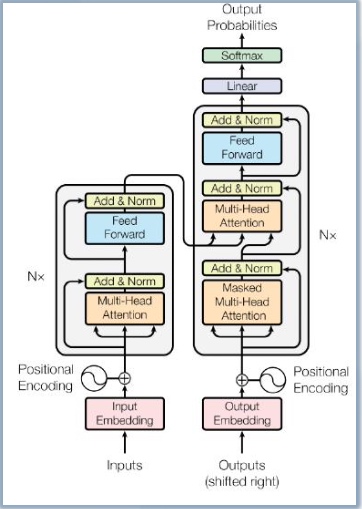
Transformer模型架构如下图
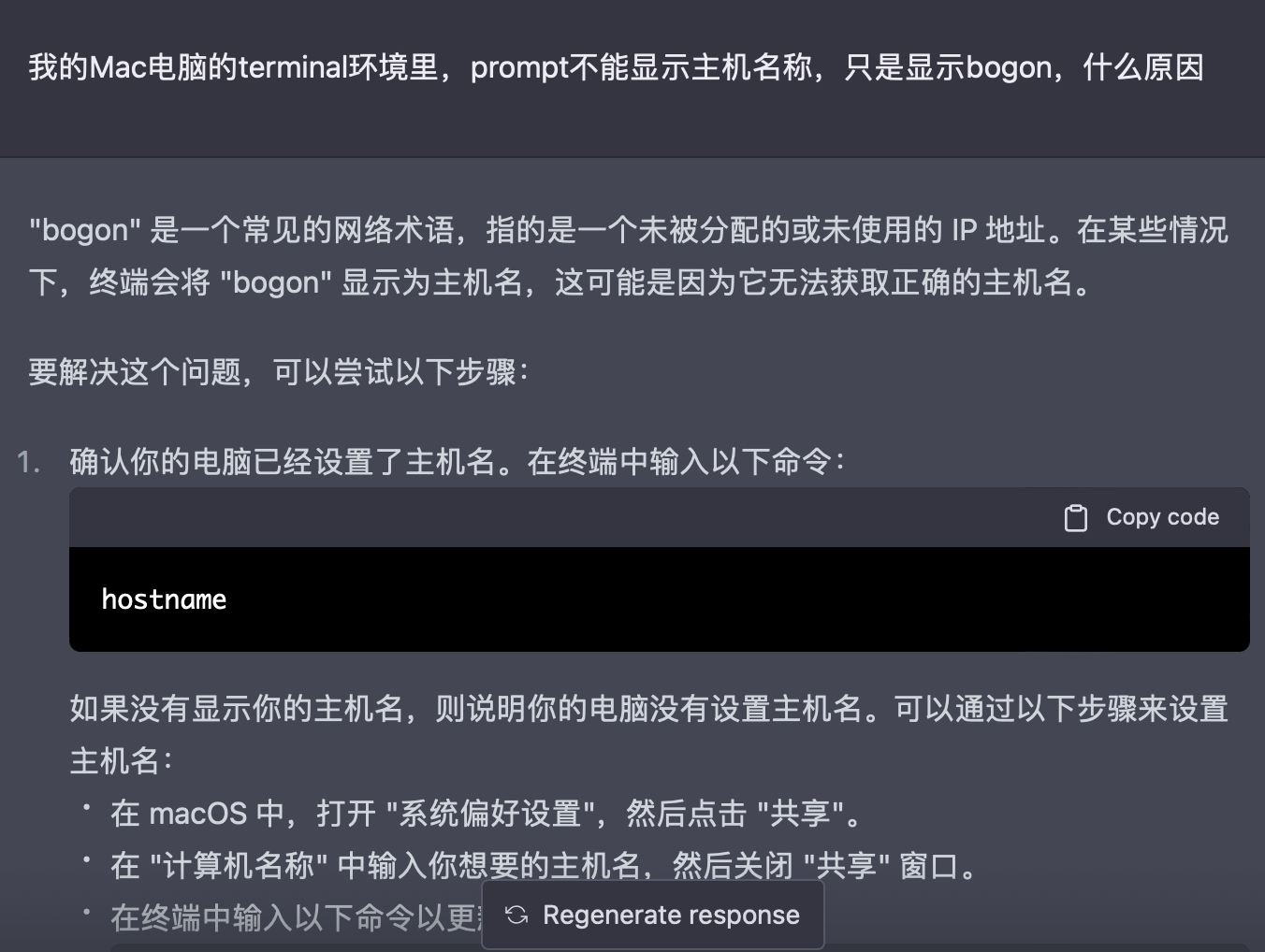
间隔2-3个月后,重新开始编程遭遇的最常见问题是,是环境搭建

首先遭遇的是tkinter问题,如下所示
import _tkinter # If this fails your Python may not be configured for Tk
在stackoverflow上搜索,大部分答案给出的都是你没有安装好tkinter这个库,解决的方式也很简单,用brew安装
但是对我而言,问题没有这么简单,因为我执行这个命令后,出现的是新的错误提示
fatal: not in a git directory
Error: Command failed with exit 128: git
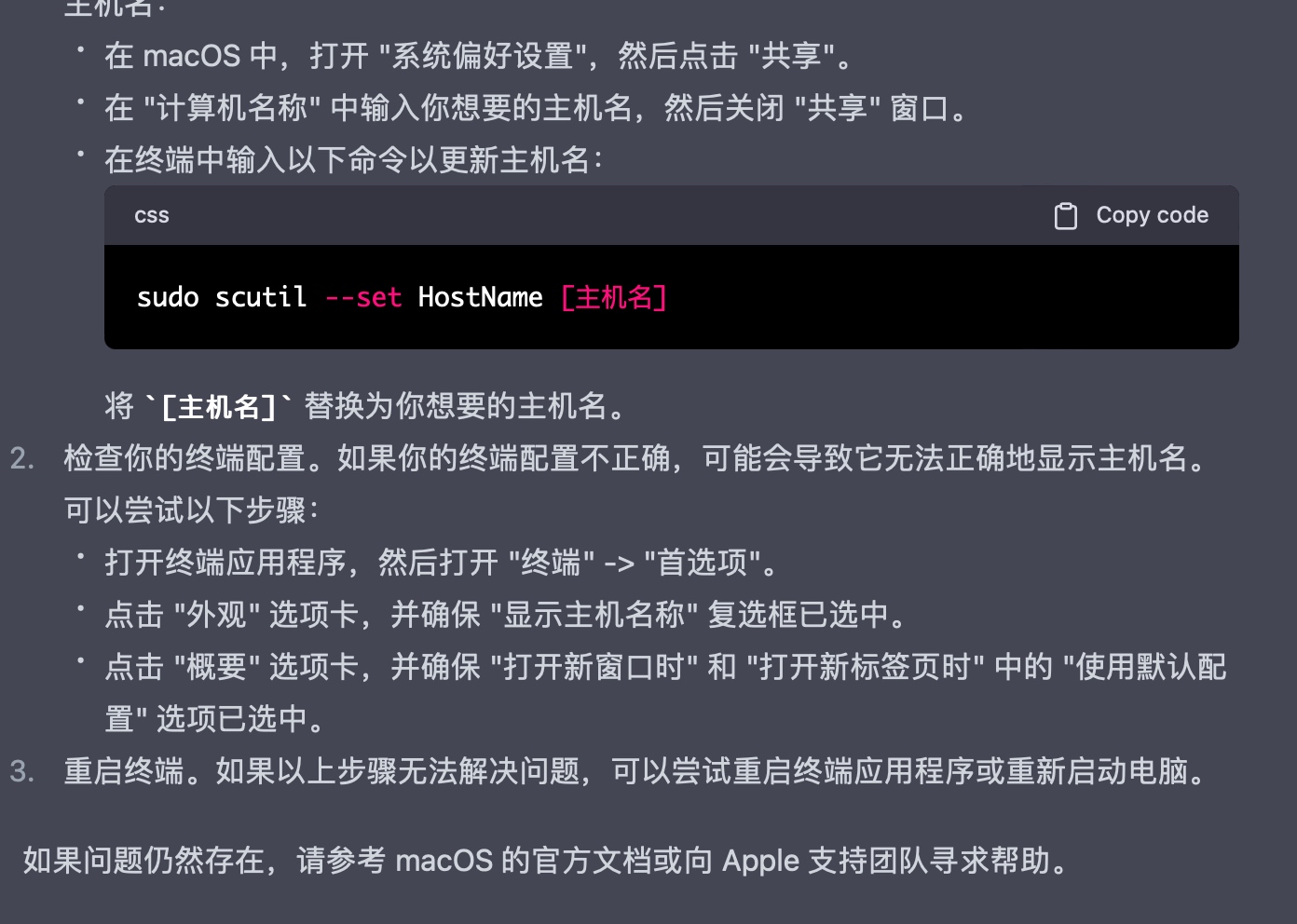
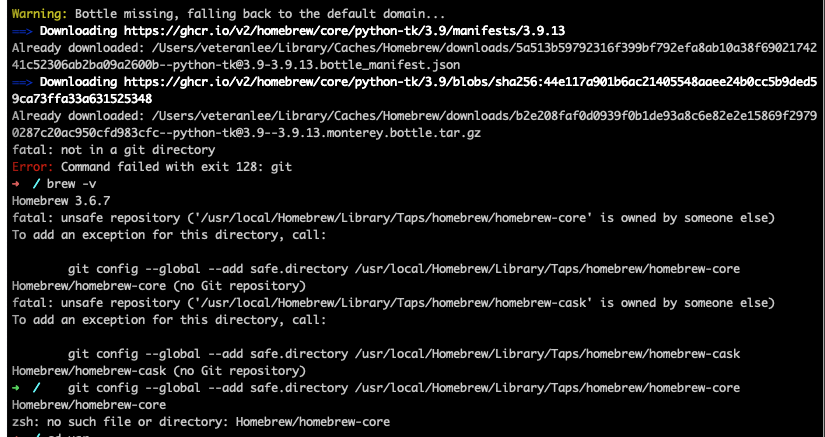
参考下面reference里小哥的分析,这是因为homebrew的组件homebrew-core和homebrew-cask没有被识别为Git仓库。
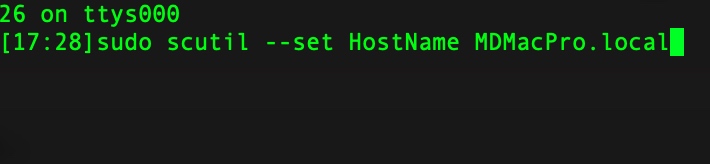
解决办法也很简单,直接按照brew的提示就好,输入
brew -v
按照提示来操作即可,如下图
怎么,还是报错,因为我copy如上命令时,没有发现最后一行其实是没有"/"链接的,因此会出现no such file or directory的提示,只要copy正确的命令即可

下来,就是正常安装
brew install python-tk
这样就完事了吗,当然不行,执行flask run,下面报错没有user这张数据库表,那么显然是数据库的问题了
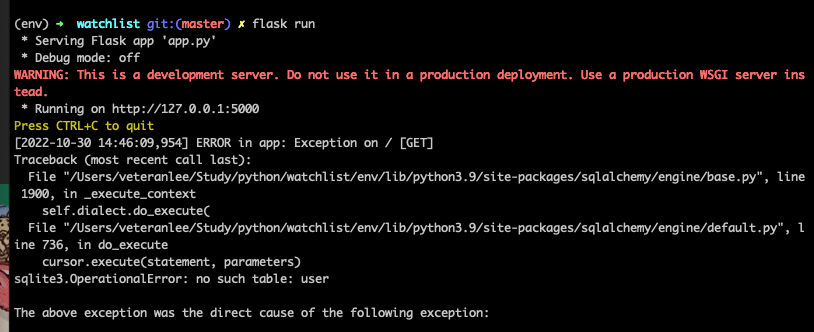
因为我们使用的是SQLAlchemy的数据库,因此我们需要先建立一个数据库文件。
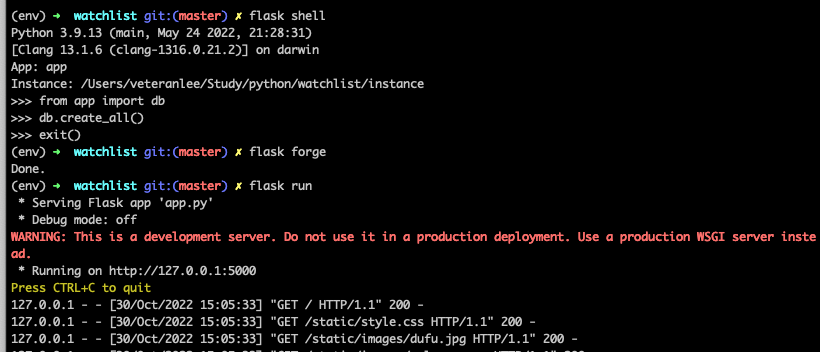
同时,我们会在目录下发现一个名为data.db的文件,这个文件名称来自app.py中的app.config函数
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(app.root_path, 'data.db')
时隔多日,重启flask学习,这次打算严格按照如下技能要求自己
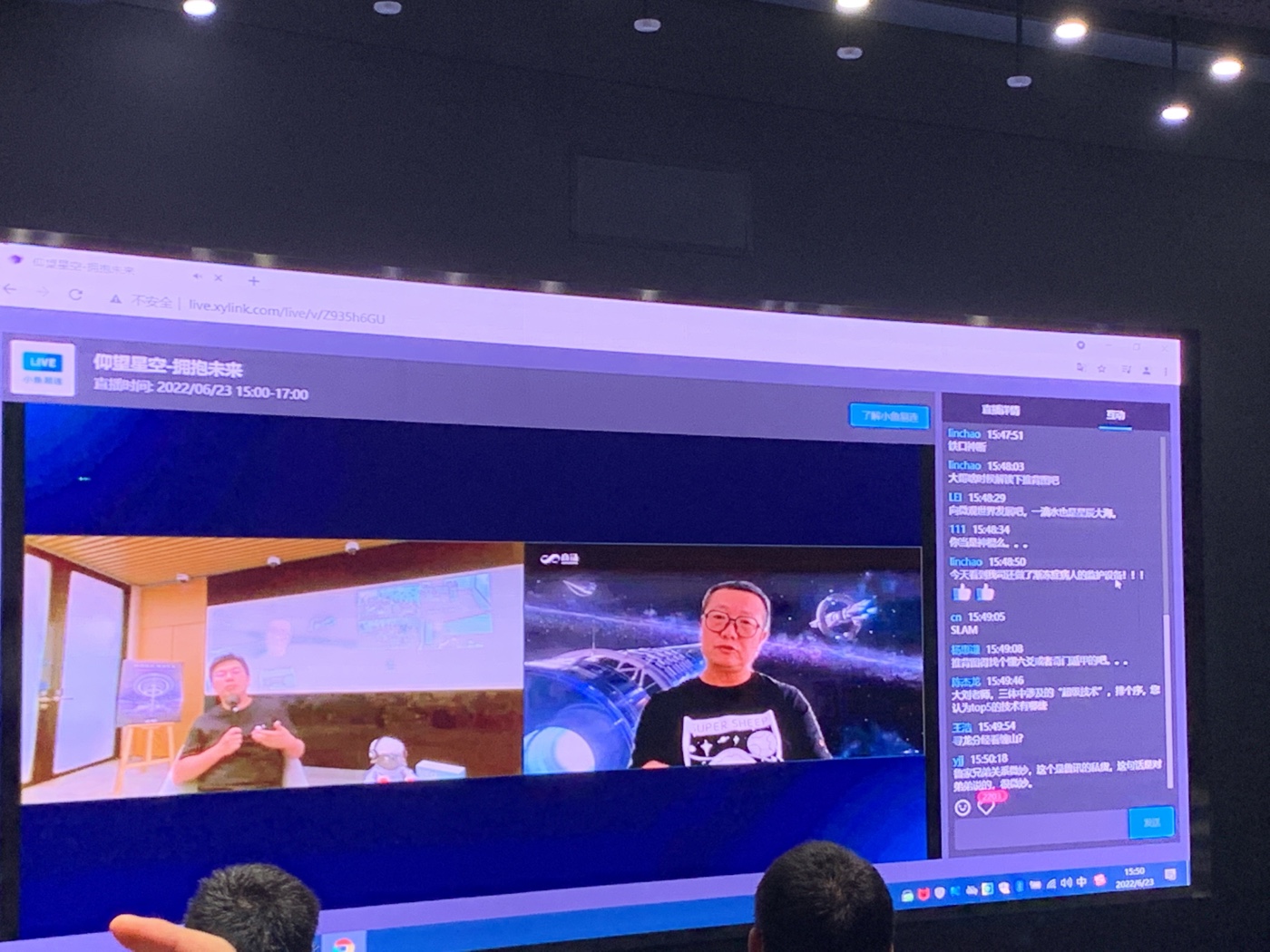
2022-06-23 15:40:05 PM
小鱼直播
刘慈欣:在没有实现的技术中,差别是巨大的。星际移民的技术和恒星移动的技术差异非常大,类似我们现在和石器时代农业技术的差异
刘慈欣:三体里的名字,都是随意的,经常会从同事的名字里改个姓就好了。我一遍遍回忆曾经敬畏过的经典作品,我现在几乎可以肯定,哪些大师们没有想那么多。
刘慈欣:现在的ai真的有用了,以前的ai像个玩具,比如人脸识别啊,具体我也举不出来。至少现在,ai在进入我们的生活。如果一直发展下去,可能在某一个节点发生巨大变化。我印象我在西站一个酒店,点外卖,机器人给我送餐,我很惊讶它怎么上的电梯。
现在看来,以前很弱的人工智能完全给我们带来改变。举个例子,无人机技术很早就有,现在进入战争、生活。我相信人工智能也是如此。
xuli:根据调动资源来衡量,增强的人类,不会遗忘,背后依托一个超算中心
刘慈欣:当一个技术出现,似乎有选择出现。但是我认为不存在,因为我们没有选择,开始我们会认为这是非人的选择,但是后续我们只能选择,否则没有办法生存下来。
刘慈欣:我们现在最科幻的,不是宇航员上天,而是流浪汉用智能手机。所以说技术改变人类。
刘慈欣:非生物智能。人工智能这个定于有个问题,因为它不一定像人,就像在站台上等一列高速行驶的火车,他经过时候,看起来像人工智能,离开后就远超人工智能。
刘慈欣:蚂蚁看我们,不认为我们有智能。在他们眼里,人类不会各种筑巢、搬粮食,只会在一个方块上点来点去。
xuli:ai可解释性,为什么是这个算法,骑自行车现在的可解释性在哪里?ai可以改变人类认知,比如下围棋,模仿go的下法。
刘慈欣:中国历史以前上一条线,无非城头变幻大王旗,没有未来的概念,昨天今天明天都一样,现在则有了未来的概念,回顾我们小时候的生活,简直不可思议。
刘慈欣:人类的感知是线性的,对于指数级增长没有感觉。
选择火星,火星和甘肃、新疆的景色差别不大。
大刘:如果ai觉醒,是跳跃性的,就没法按照人类中心主义去掌控这个世界了。