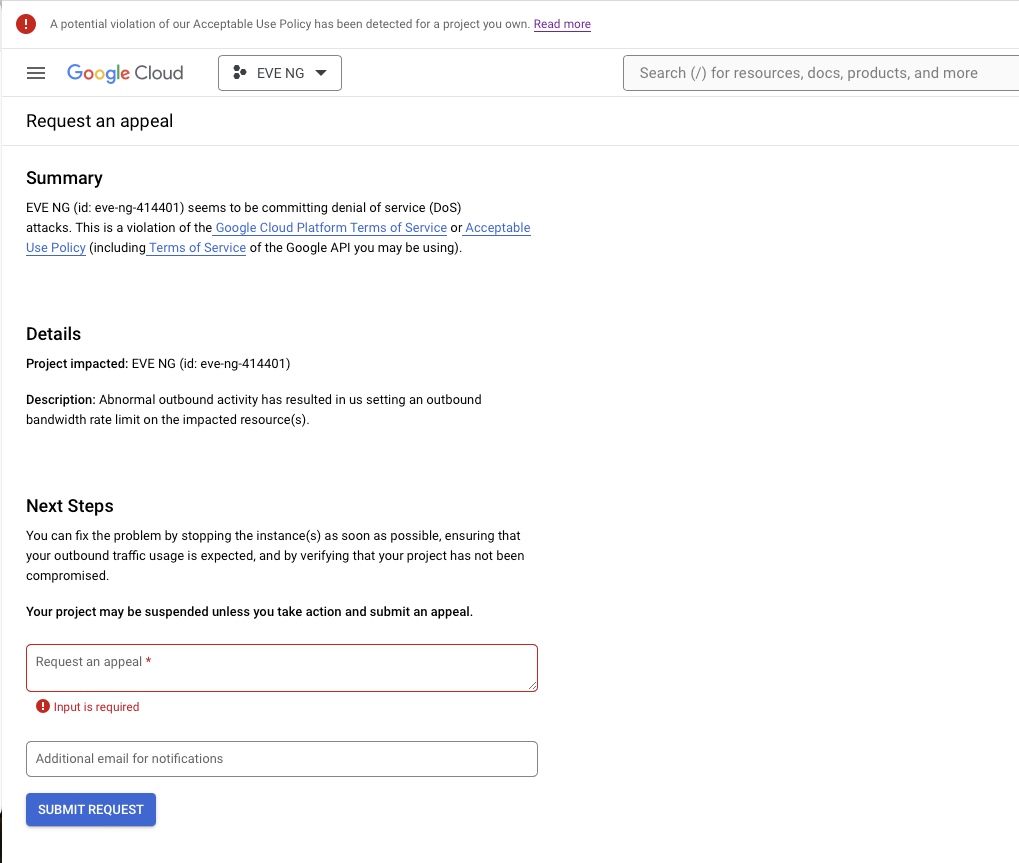
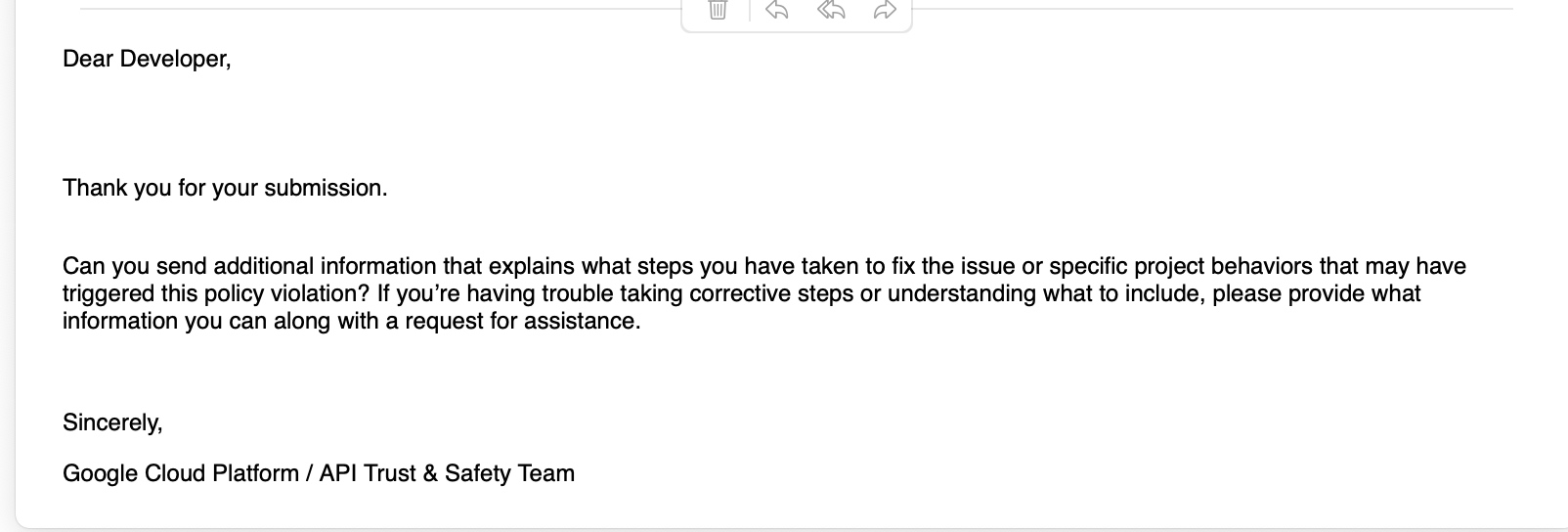
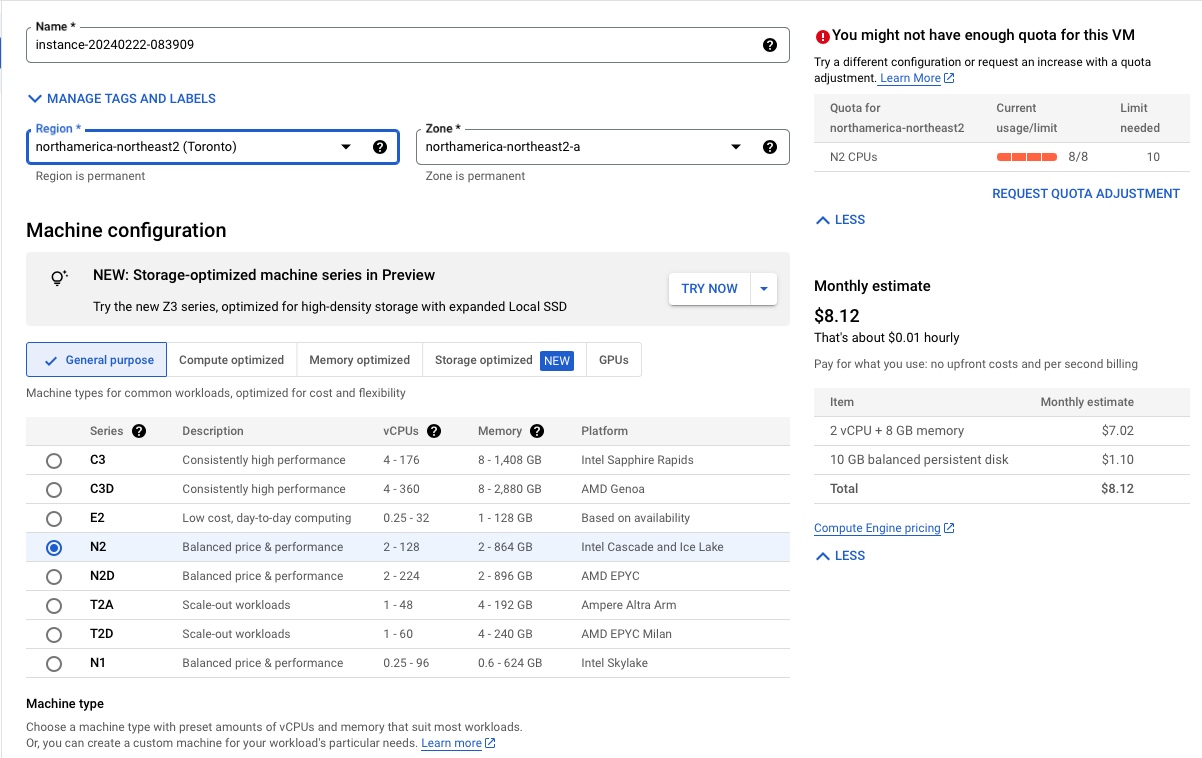
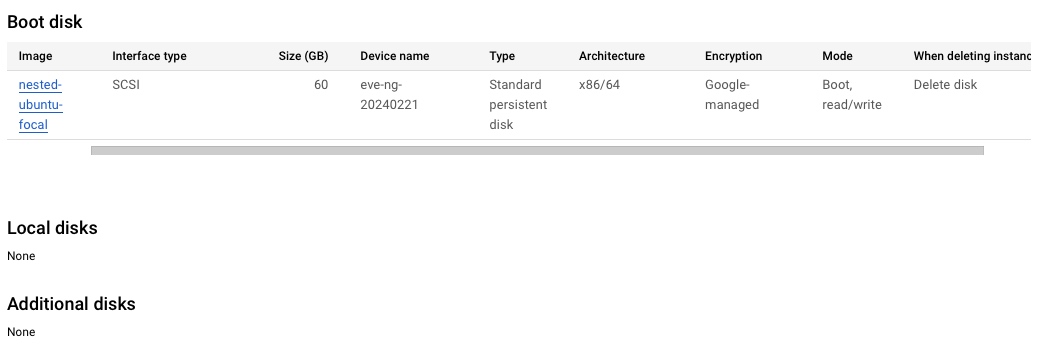
因为要使用决策树,没法对非数值进行处理,所以需要把dataframe中的一些数据转换成数值,使用了如下code
from sklearn.preprocessing import LabelEncoder
from collections import defaultdict
d = defaultdict(LabelEncoder)
X_trans = X.apply(lambda x: d[x.name].fit_transform(x))
X_trans.head()
ChatGPT4解释如下
The expression lambda x: d[x.name].fit_transform(x) is a compact way of applying a function to each column of a pandas DataFrame. Let’s dissect this expression further to understand how it works in the context of transforming categorical data into numerical format using LabelEncoder in a Python environment.
The lambda Function
A lambda function in Python is a small anonymous function defined with the keyword lambda. The syntax is:
lambda arguments: expression
In this case, the lambda function has one argument x (representing a column of the DataFrame) and the expression involves applying the fit_transform method from a LabelEncoder instance to x.
How the lambda Function is Applied
x: Within the context of theapply()method,xrepresents each column in the DataFrame one at a time. For instance, if the DataFrame has columns "Color" and "Size",xwill be the "Color" column data in one iteration and the "Size" column data in the next.
Usage of d[x.name]
-
d: This is adefaultdictcontaining instances ofLabelEncoder. The use ofdefaultdictensures that if aLabelEncoderfor a particular column name does not exist, it will automatically create a newLabelEncoderinstance without raising an error. -
x.name: This attribute fetches the name of the column currently being processed (like "Color" or "Size"). -
d[x.name]: This retrieves theLabelEncoderinstance for the column namedx.name. If it’s the first time this column is being accessed,defaultdictinitializes a newLabelEncoderfor this key.
The fit_transform Method
fit_transform(): This method is part ofLabelEncoderand serves a dual purpose:fit: It learns the mapping from the labels in the column to integers. For example, for a column with labels ["Red", "Blue", "Green"], it might learn the mapping Red -> 0, Blue -> 1, Green -> 2.transform: It then transforms the labels into these integers based on the mapping it has learned.
Putting It All Together
When you call X.apply(lambda x: d[x.name].fit_transform(x)), it performs the following steps for each column in DataFrame X:
- Accesses each column as
x. - Fetches the
LabelEncoderfor that column byx.name. - Applies
fit_transformto the column, converting text labels into integers. - Returns a new DataFrame where each text label has been replaced by an integer.
This method is particularly useful when preparing data for machine learning models, which generally require numeric input features rather than text labels. The transformation is done in-place and efficiently for each column, utilizing the flexibility of defaultdict and the functionality of LabelEncoder.